Courses/Computer Science/CPSC 457.F2013/Lecture Notes/Scribe3
| Week1 | Week2 | Week3 | Week4 | Week5 | Week6 | Week7 | Week8 | Week9 | Week10 | Week11 | Week12 | Week13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 09/13 | 09/16 | 09/23 | 09/30 | 10/07 | - | 10/21 | 10/28 | 11/04 | - | 11/18 | 11/25 | 12/02 |
| - | 09/18 | 09/25 | - | 10/09 | 10/16 | 10/23 | 10/30 | - | 11/13 | 11/20 | 11/27 | 12/04 |
| - | 09/20 | 09/27 | 10/04 | 10/11 | 10/18 | 10/25 | 11/01 | 11/08 | 11/15 | 11/22 | 11/29 | 12/06 |
Contents
- 1 Introduction
- 2 Week 1
- 3 Week 2
- 4 Week 3
- 5 Week 4
- 6 Week 5
- 7 Week 6 [Scribe 3 Away On A Conference, Please refer to Scribes 1 & 2 for Notes]
- 8 Week 7
- 9 Week 8
- 10 Week 9
- 11 Week 10
- 12 Week 11
- 13 Week 12
- 14 Week 13
Introduction
Hi all! I am Scribe#3 aka Riane Vardeleon.
- concentration in HCI
- Computer Science Undergraduate Society Executive Officer
- works at the Interaction Lab
I hope you find my notes useful. If there are any errors or mistakes in my notes please feel free to let me know OR you can edit it yourself by clicking "Edit" at the top of the page (this is assuming you have a ucalgary Wiki account, which you can easily create).
If you have any questions, comments, concerns, scribes, jokes and/or stories you can direct them to me via email at vrvardel[at]ucalgary[dot]com
Week 1
September 13: What Problem Do Operating Systems Solve?
Why OS?
- Abstract OS concepts relative to mature, real-world and complex pieces of software
- "Abstraction is the key to understanding complexity."
- Translates concepts to hardware with real limitations
Fundamental Systems Principles
- OS is about the software that operates some interesting piece of hardware.
- 1. Measurement
- 2. Concurrency
- being able to tell or think that the system is doing more than one thing at a time
- 3. Resource Management
- memory, CPU, file systems
- managing these and keeping them coherent
Main Problem
- What main problem do operating systems solve?
- 1. Manage time and space multiplexed resources
- What is a time multiplexed resource?
- What is multiplex
- splitting into different channels, “sharing” (more on time multiplex)
- CPU (time multiplex resources)
- caches, states make them space multiplex, which are also shared among process, etc.
- Hard drive (data storage) - space multiplex
- Mediate hardware access for application programs
- abstraction
- Load programs and manage execution
- turn code into running entities
- 1. Manage time and space multiplexed resources
What is a Program?
- source code?
- assembly code?
- machine code/binary?
- what are the differences between the above three?
- a process ?
- common def: a program in execution
Command Line Demo
Program Example: addi.c
int main (int argc, char* argv[])
{
int i =0;
i = i++ + ++i;
return i;
}
- i = i++ + ++i, undefined behavior; the output of this statement is completely dependent on the compiler
- answer can be: 1, 2, or 3, it just depends on what the compiler actually does
- addi.c is the program
- addi, binary/machine code
Commands
| Cmd Prompt | Objective | Example |
|---|---|---|
| mkdir dir_name | create a new directory | mkdir CPSC457 |
| cd dir_name | change directories | cd .. |
| editor_name -nw filename | run emacs and creates the new given file | emacs -nw addi.c |
| editor_name filename & | open the given file in the specified editor & makes the program run int eh background |
emacs addi.c |
| gcc -Wall -o filename filename.c |
C compiler
|
gcc -Wall -o addi addi.c |
| gcc -S filename.s | outputs x86 assembly code | gcc -S addi.s |
| cat filename | concatenate files or input to an output | |
| hexdump -c filename.c | shows the contents of the elf file (filename) | hexdump -c addi.c |
| objdump -d filename | disassembly of code | objdump -d addi |
Week 2
September 16: From Programs to Processes
Command Line Demo
Pipes
- Using pipes allows us to use the output of one command to become the input of another command.
- cmd_prompt | cmd_prompt2
- output of cmd_prompt becomes the input of cmd_prompt2
History
| Cmd Prompt | Objective | Comments |
|---|---|---|
| history | show history of commands | too many lines, hard to read through |
| more | indicates sequence of output of history | press 'q' to quit |
| gawk '{print $2}' | produce a frequency distribution of command history | awk is the grandfather of perl |
| gawk '{print $2}' | wc | counts the output | --- |
| gawk '{print $2}' | sort | sorts output | based on output types |
| gawk '{print $2}' | sort | uniq -c | remove duplicates | includes count of each entry |
| gawk '{print $2}' | sort | uniq -c | sort -nr | numerically sorts output | -n sorts from smallest to largest -nr sorts from largest to smallest (reverse order) |
Program Example: hello.c
#include <stdio.h>
int main(int argc, char* argv[])
{
printf(“hello, 457!\n”);
return 0;
}
MakeFile Example
all: hello
hello: hello.c
gcc -Wall -o h hello.c
clean: ** this is currently incomplete, will update soon! **
Commands
- Some of these commands are programs
- Others are just functionality
| Cmd Prompt | Objective | Example | Comments |
|---|---|---|---|
| man cmd_prompt | reveal manual pages for specified command | man wc | --- |
| ls | lists the file contents of the current directory | --- | --- |
| ll | same as ls but provides a bit of extra information regarding each file | --- | --- |
| clear | clears terminal screen | --- | --- |
| make makefile | helps to control process of building a piece of software | make hello | --- |
| readelf filename | displays information about elf files | readelf hello | --- |
| more | --- | --- | --- |
| exit | terminates shell process | --- | --- |
| file filename | decides and outputs type of file | --- | --- |
| gdb | debugger | --- | --- |
| su | switch user | --- | --- |
| stat | gets information about files | --- | --- |
| ps | outputs which processes are currently active | --- | --- |
| ps aux | prints all running processes and programs | --- | --- |
| wc | outputs counts in the format lines words</> <i>bytes; lines = # of active programs | --- | --- |
| pstree | displays a "tree" which shows the relationships between process | --- | --- |
| top | gives a live view of what programs are running, what each program's resource usage is, etc. | --- | --- |
| sftp | secure ftp | --- | --- |
| df | tells you about the usage of system storage of the machine | --- | --- |
| ifconfig | tells about the state of the network | --- | --- |
| diff | shows/reports the difference between two files/patches | --- | --- |
| yes | outputs a string repeatedly until killed | yes hello | to kill
|
September 18: What is an Operating System?
Readings
A Tiny Guide to Programming in 32-bit x86 Assembly Language
A Whirlwind Tour on Creating Really Teensy ELF Executables for Linux
- how to speak machine language directly to the OS
MOS 1.3: Computer Hardware Review
MOS 1.6: System Calls
MOS 1.7: Operating System Structure
Recap (From Programs to Processes)
- Focused on:
- command line agility
- transformation of src code to an ELF
- Why?
- give an overview of some commands from cmd line
- give an idea of the rich variety of commands (from ps to stfp)
- demonstrate the use of Unix manual (man cmd)
- use it to drive a discussion of processes (ps, pstree, top)
- observe the transformation of code to binary (+reinterpretation)
- observe the coarse level-detail of ELF file
- use strace to run a program
What is an Operating System?
- a) a pile of src code (LXR)
- b) a program running directly on hardware
- c) a resource manager (multiplex resources, hardware)
- d) an execution target (abstraction layer, API)
- e) privilege? supervisor?
- f) userland/kernel split
System Diagram
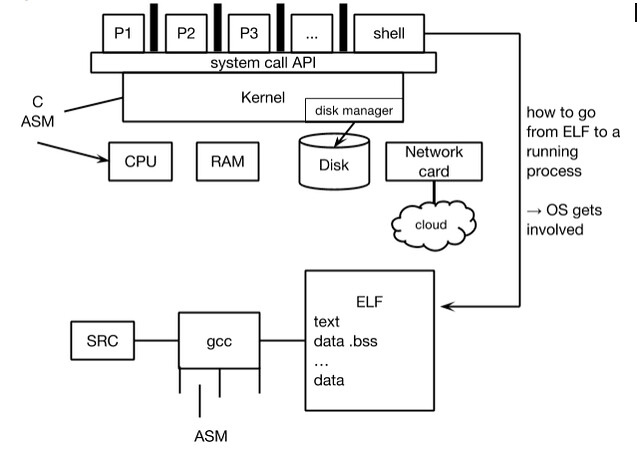
What is Kernel? (High Level)
- low level language the talks to hardware (student answer)
- C, ASM (which is specific to the CPU it will run on)
Kernel is...
- piece of software
- interface to hardware
- supervisor
- central location for managing important events
- provides a level of abstraction
- defines system call API (application programming interface)
- don’t want to have to code that for every program, so it becomes a part of system calls
- protection
- decides which programs/applications get certain resources/priority
- force protection or isolation between processes
- e.g. should P1 read/write/manip P2?
- There are no set rules on what goes into the kernel, so why not put everything into the kernel?
- Complexity
- adds to the complexity making it more error prone
- harder to debug later
- Mistakes, inconsistencies and unreliability in code can affect every process in the machine
strace
- a tool for measure the state of a process
- measuring interaction of user level apps with kernel via system calls
- observe system call interface in action
- each line starts with name of system call
- each line ends with return/output value of system call
- Note: notation write(2) refers to system call called write in section 2 of the manual. All system calls are in section 2
September 20: System Architecture
Finishing up “What is OS?” Discussion
- 1. How does a kernel enforce these divisions?
- 2. What is the necessary architectural support for basic operating system functionality?
- 3. How do processes ask the operating system to do stuff?
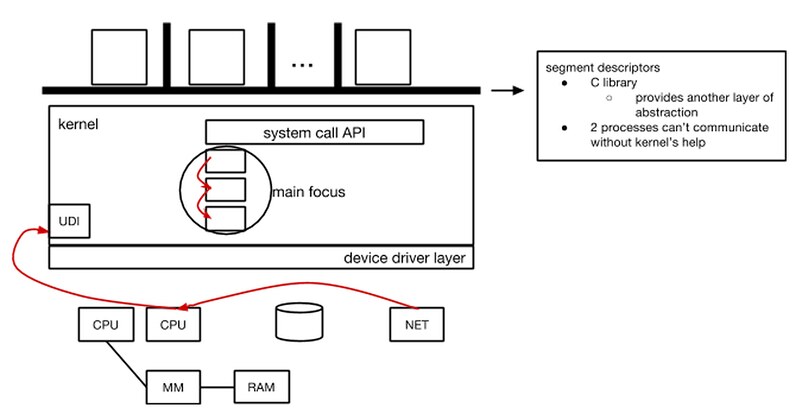
- Suspend discussion thread of “how does a program become a process?” at “the fork/execve system calls” fwd pointer to system calls
- What physical support do you need in the CPU to make the divisions between process a ‘reality’?
What separates user and kernel mode
- CPL bits in CPU
- LXR
- takes source code as input, makes it easier to navigate through source code
- has documentation as well
The Kernel
Demo Example
kernel 2.6.32 (source, scientific linux)
tar -xf linux-2.6.32.tar
Note: Compiling takes a long time so make sure to plan accordingly before you compile.
Main directories in Linux-2.6.32
- arch - architectural specifics
- kernel - main components (scheduling)
- mm - memory management
- fs - file system
- scripts - scripts for building the kernel (drivers, etc)
There is lot of source code in the kernel to dig through, LXR is a nice tool to use for this.
Overview / Refresh of x86
Program Example: silly.c
#include<stdio.h>
int main(int argc, char* argv[])
{
int i = 42;
fprintf(stdout, “hello, there \n”;
return;
}
makefile
all: silly.c
silly: silly.c
gcc -Wall -g o silly silly.c
clean: @/bin/rm -fm silly.c
x86
- General Purpose registers (32bits)
- eax, ebx, ecx, edx, edi, esi
- ebp, esp have specific purposes
- eip, cannot be accessesd (written into drectly), records location for next instruction
- eflag
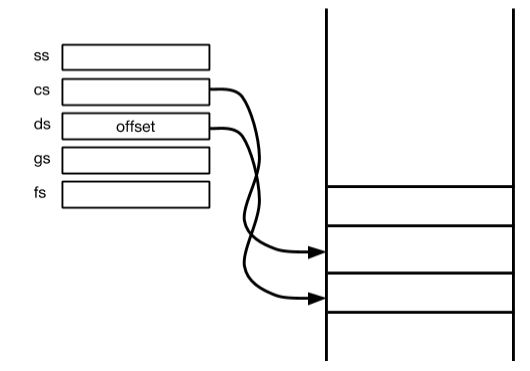
- Segment registers
- SS - segment selector for stack
- CS - code segment
- DS - data segment
- GS - general segment
- FS - general segment
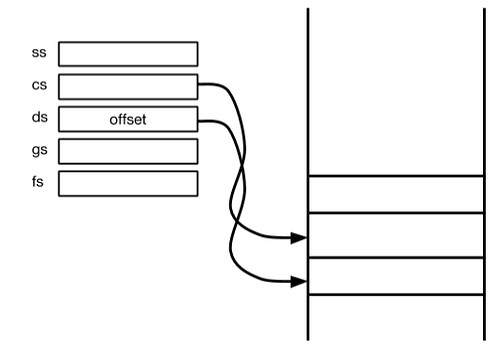
- store what’s called segment select
- supports the division between kernel space and user space
- numbers in the register (not address space)
- offsets to a data structure in memory called GDT (Global descriptor table)
- stored in gdt segment descriptor
- sement is a portion of memory
- part of CPU’s job is to provide access to segments
- splitting memmory into distinct regions called segments
- properties of segments - defines essence of the segment (where its stored
- have start address (base)
- limit - how far it extents
- DPL (descriptor privilege - 2bits [00,01,10,11])
- are the only thing that stands between userland and kernel, nothing else does this
- set up GDT - to provide diff memory segments for user programs (takes a portion of memory)
- set up IDT (interrupt descriptor table) -
- services requests/events
- kernel constantly gets interrupts from user and hardware → kernel needs to be able to deal with these interrupts appropriately
- software initiated interrupts are called Exceptions
- e.g. CPU receives interutpts from network card, cpu doesn;t know what to do, OS tells it what to do (go to memory and look for the particular entry regarding the interrupt (in IDT), it contains an address for instructions on what needs to be done for that interrupt)
- if you wanted to you can build an os solely based on gdt and idt
- allows kernel to do silly things
- GDT IDT live in kernel memory
- IDT address of functions
IA-32 Supervisor Environment
Programmable Resources
- IDTR - contains address in memory containing IDT
- GDTR - contains address in memory containing GDT
Week 3
Sept 23: System Calls
System Call
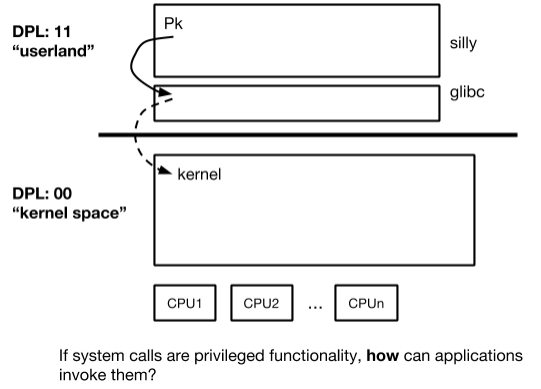
Key Questions
- 1. How does a kernel enforce the division between user and kernel
- need a well established transition
- 2. What is the necessary architectural support for basic operating system functionality
- 3. How do processes ask the operating system to do stuff?
System Call API
- processes
- cannot do useful work w/o invoking a system call
- in protected mode
- only code at ring zero can access certain CPU functionality and state
- OS implements common functionality and makes it available via the syscall interface (application programs thus do not need to be privileged and they do not need to reimplement common fun)
- 1) API: a stable set of well-known service endpoints
- 2) As a "privilege transition" mechanism via trapping
- not a direct jump from user to kernel
- How does this happen?
The Set of System Calls
- about 300 system calls on Linux
- only a relatively small set are frequently used
- Where is the list?
- /usr/include/asm/unisted_32.h
Command Demo
Program Example: silly.c Modified
#include <stdio.h>
// used for syscall
#include <unistd.h>
int foobar(int a, nt b)
{
return a+b;
}
int main (int argc, char*argv[])
{
int = 42;
// function call
i = foobar(7,8);
// system call
write(1, "hi from syscall\n", 16);
fprint(stdout, "hello, there, %d \n", i);
return 0;
}
Invoking FUNCTION Call
- (see assembly src code)
- As the caller need to be able to comma arguments with the callee
- through the stack
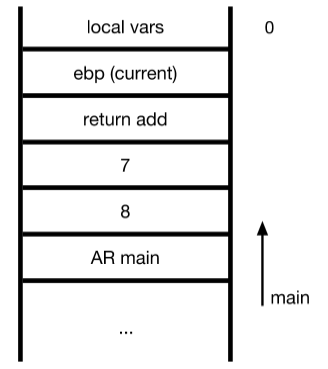
- activation records (stack grows down to 0)
- set up AR
- call foobar
- arguments are pushed in reverse order
- in order to create a chain on AR
- save current value of EBP
- update ebp (take current val of esp and store in ebp
- … continue with actions … (adding a+b)
- pop ebp
- return
- no change in privilege
- applications are free to do whatever (this is for function calls)
Invoke SYSTEM Call
- (see assembly src code)
- Invoking a library call in c called write
- redirecting to glibc
- cannot just call syscall
- As in calling functions the convention requires that arguments be given and stored somewhere
- DPL needs to somehow change from 11 to 00
- need something that will allow software interrupts
- CPU will notice the interrupt
- Kernel creates IUT
- CPU services instructions
- changes DPL 11 to 00 to give access
- No direct transfer
- The following example is a convention on calling system calls
Program Example: write.asm
;; write a small assembly program that calls write(2) ;; write(1, "Hello, 457\n", 11); ;; eax/4 ebx/1 ecx/ edx/11 BITS 32 GLOBAL _start SECTION .data mesg db "hello, 457", 0xa SECTION .text _start: mov eax, 4 ;; number of syscall ;; how do you know this number? ;; more /usr/include/asm/unisted_32.h mov ebx, 1 ;; stdout mov ecx, mesg ;; label mov edx, 0xb int 0x80
- nasm -f elf32 write.asm
- output 32 bit elf
- ld -o mywrite write.o
- make an executable
- ./mywrite
- Outputs:
- <i.[file output]
- Segmentation fault</i>
- after adding the following three lines in code, segmentation fault doesn't appear
mov ebx, eax mov eax, 0 ;; exit status int 0x80
- When would you want to write ams code for system calls
- short codes
- glibc
- if you don't have the programming environment
- if it doesn't have compiler functionality
- malware
- essentially injecting code into someones process
- shell (x86 code invoking system calls)
- Driver is nothing more than a set of functions and data in the kernel
- you would write this in C
- no need for system calls because you're already in the kernel when you want to execute drivers
Program Example: mydel.asm
;; try to call unlink on (? something) ;; unlink(“secret.txt”)
BITS 32 GLOBAL _start ;; defines symbol for entry point of program SECTION .data SECTION .text _ start mov eax, 0xA mov ebx, filename int 0x80 mov ebx, eax mov eax,1 [ some lines missing, will update ]
- echo “secret” > secret.txt
- how does unlink name
- delete a name and possibly the file it refers to
- need to know syscall number (10)
- locate unstd_32.h
- more /usr/include/asm/unisted_32.h
Sept 25: An Introduction to Processes
Learning Objectives
- 1. What is a Process?
- 2. How does a program become a process?
- 3. Process Definition and Properties
- 4. Look at kernel code for PCB and fork()
Why does an OS exist?
- load and run user programs and software applications
- process creation and control is a central defining characteristic of any OS
Terminology
- In Linux
- task is generic term refers to an instance of threads or processes
- process and thread are represented exactly the same way
- lightweight process - idea that a process is a thread and a thread is a process
- only real difference is that a group of lightweight processes may share access to the same process address space (i.e. set of memory regions)
- refers to every executable task
What is a Process?
- Definition by construction
- “a program in execution”
- program counter (e.g. $eip)
- CPU context (i.e. state of CPU registers)
- computational info for a particular process
- state of CPU
- current happenings in kernel instructions
- set of resources such as open files, meta data about the process state (e.g. PID)
- memory space (i.e. process address space)
- dynamic memory (stack)
Process Control Block
- kernel memory
- in Linux: task struct
- set of meta data about a process or running process
- vital parts that enables an OS to manage every process on a machine is a set of meta data that records
- task struct
- See LXR (http://lxr.cpsc.ucalgary.ca/lxr/#linux+v2.6.32/include/linux/sched.h#L1215)
- CPU cannot run more than one thing at a time
- kernel manages this
- OS
- interprocess communication (concurrency), a process could be waiting for something
- not all processes are ready to execute
- again kernel manages it
- inside this there are references that help make decision on things like task priority and tracking information
- mm struct
- point to a set of memory regions//pages that define the address space
- relationships between processes is another important thing that the OS needs to keep track of
Process States
- “Life cycle of a process”
- 1. TASK_RUNNING: process is eligible to have the CPE (i.e. run)
- denotes both a running and runnable state
- 2. TASK_INTERRUPTIBLE: process sleeping (e.g. waiting for I/O)
- 3. TASK_UNINTERRUPTIBLE: same as above, but ignores signals
- 4. misc: traced, stopped, zombie
- 1. TASK_RUNNING: process is eligible to have the CPE (i.e. run)
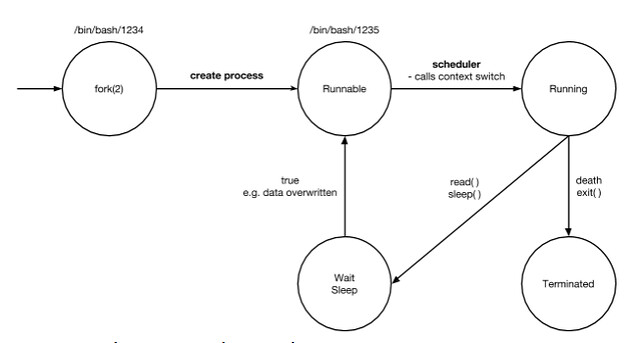
- start when a process is created
- duplicate process
- now have two processes running
- bash is the program that is running
- process now in a runnable state
- eligible to be given a CPU (doesn’t necessarily have a CPU)
- scheduler decides that a process can be run
- calls context-switch
- put process on CPU
- scheduler loads all registers/instructions/etc. to the CPU
- process is now running in a CPU
- one of a few things can happen
- invokes a system call to kill/terminate itself
- wait/sleep
- invokes a system call: e.g. read(), sleep()
- can become return to the runnable state
Process Relationships
- pstree
- why does pstree exist?
- OS startups
- one of the results: creation of init process
- has a process ID (PID) of 1
- every other process descends from init
- startup scripts
- ELF files
- when the scripts finish you have a set of processes running on a machine (e.g. log in form, etc.)
- gnome
- has several dash sessions
Process Creation in Linux
- processes satisfy all user requests
- quick creation is important
- 3 mechanisms exist to make process creation cheap:
- copy on write (read same physical pages)
- lightweight processes (share kernel data structures)
- same code, same data
- vfork: child processes that uses parent PAS, parent blocked
- what happens when a child dies, but parent needs to gather some final information from it?
- parent never knows if the child was able to execute what it needed to do
- zombie state child sticks around in order to provide the needed information to the parent until it is ready to be terminated
- what happens when a parent dies, but its children live on?
- possible outcomes
- parent dies, child dies
- parent dies, give child another parent
- solution: reparent the child process to init
- this will happen unless there is another thread/process (from the same set) that can parent the child
Demo
semantics of fork(2) myfork.c
#include<stdio.h>
#include<unistd.h>
int main(int argc, char* argv[])
{
pid_t pid = 0;
pid = fork();
if (0==pid)
{
//child
fprint(stdout, “hey, I’m the child”);
}
else if (pid > 0)
{
//parent
fprint(stdout, “hey, I’m the parent”);
}
else
{
//failed
}
}
- parent in this case is a.out whose parent is the base
Sept 27: The Process Address Space
Thoughts
- 1. Much of what OS does is
- namespace management: alloc, protect, cleanup/recycle, etc.
- CPU
- Memory
- files
- users
- if we expect these services, then the kernel must contain code + data supporting it
- 2. What is a process?
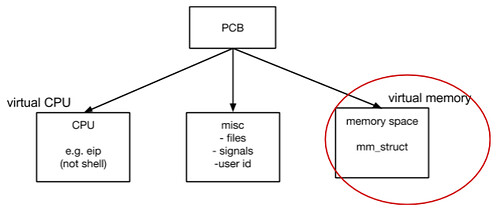
- 3. What makes these lines real?
- How many things can you address with 32 bits?
- 232 (4 billion ~)
- Linear representations
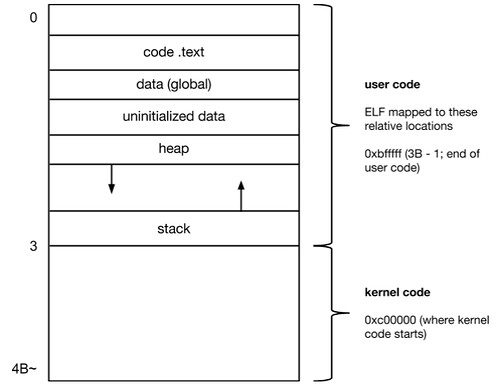
- virtual memory
- can have a lot of physical memory
- OS takes contents of ELF and write it in the process address space
- support for finding address space
- 4 segments, difference lies in DPL bit
- somehow there’s a disconnect between a virtual address to the actual physical address space it is mapped to
Consider:
int x = 0x1000;
main (...)
{
x = 0x3000;
}
//one.c
//one
//cp one two (// copy one to two)
//bless two
- first x and second x, two separate programs
- yet they share the same address space
- translation process occuring
- same process address space
- but each have separate physical address space
- lead processes to believe that they have sole access to virtual address
- supported by mm

Why have a PAS abstraction?
- giving userland programs direct access to physical mem involves risk
- hard coding physical addresses in programs creates obstacles for cocurrency
- most programs have an insatiable appetite for memory, so simply segmenting available physical memory still leads to overcrowding
- need a way to organize processes
PAS (Process Address Space)
Key Question
- How do you multiplex memory?
pmap
- cmd line utility that prints out internal organization of a processes of an address space
- aka the element on that address space
- cat /proc/<PID>/maps
- r - readable
- w - writable
- x - executable
- p - private
- s - shared
- shows start and end address
- process all have their own allocated space
- gaps in memory allocation
- allow for addition of “dark pages”
PAS Operations
- fork(): create a PAS
- execve(): replace PAS contents
- _exit(): detroyPAS
- brk(): modify heap region size
- mmap()
struct mm_struct
- pointer to the address space
- memory descriptor
- set of data structures that help keep track where memory regions are
- “container” for memory regions
Week 4
Sept 30: The Process Address Space
A Process Address Space
- composed of memory areas (“memory regions” in Linux terminology)
- Memory areas are collections of memory pages belonging to particular address range
- A page is a basic unit of (virtual)memory, a common page size is 4KB
- manipulate memory in discrete chunks
- does map to a page frame in physical hardware
- allows os to manipulate memory in fixed sizes
- contains data
- How does a program actually access a particular memory address?
- assembly instruction that moves the memory address into a register (fetch, decode, excute)
- Focus: how to find memory address
- when it is fetching where is it fetching from?
- text section, which is in RAM
- MMU (memory management unit), mediates the communication between the CPU and RAM
- tricky because OS multiplexes resources like RAM and allow multiple process to use single resource
- MMU
- translate the address (i.e. 0x…) to an actual physical address in memory
Terminology
- 1. Logical Address
- has a couple of parts
- [ss]:[offset ] (ss - segment selector)
- ss corresponds to registers (we’re focusing on cs and ds that points to a location in the GDT (global descriptor table)
- 2. Linear Address (aka Virtual Address)
- a range
- can be split up and place in different physical locations
- split into three
- dir
- table
- offset
- 3. Physical Address
- an actual location in physical RAM
Example (see Dr. Locasto's Notes for this day)
- needs to know about certain data structures
- indexing into these data structures which live in kernel memory
- page directory is in the pgd in task_struct
- first 10 bits
- finds page on page tables which actually says the location of a page
- nth entry in the page directory
- second 10 bits
- tell what page I’m actually looking at
- last 12 bits
- used to index into that page
- rather than having the MMU translate an address every time it sees it, it caches it
- MMU looks into TLB (translation lookaside buffer), “have I seen this address before? yes? then I already have the physical address
- TLBs are small so you can’t cache everything
- page directory is unique to every process
- when you change processes
- there is a context switch,
- some TLBs have support for marking or tagging
- OS is free to move around mapping between virtual and physical memory
- data structures are maintained for every process
Oct 4: Virtual Memory
What is DS:0x80406dc?
- logical memory address, virtual address
- Linux uses flat segment
- series as bits that refer to index
- Where is the corresponding physical address space?
- don’t care about the physical
- OS may change these arbitrarily
Where does the problem originate
- segmentation & paging provide isolation (between kernel and user, DPL bits)
- binding between physical location and variables is broken
- processes can’t access same physical address space
Focus
- How does an OS kernel keep all these processes in memory at once?
- it doesn’t
- 1. Only limited amount of RAM
- 2. On average NNN processes
- 3. Processes don’t know how much memory they actually need
- 4. Each believes they can access at least 4GB (depending on RAM size)
- How do we keep this fiction alive?
- There’s no way to actually specify or limit the amount of memory a process can use
- Logically every variable will be in a register, right?
- false
- registers are limited but access to them is fast
- a variable can live anywhere on this “stack” (above diagram)
- it just needs to be in the right place (register) at the right time
- OS makes sure of this
Virtual Memory
- Memory can be addressed in fixed chunks: Pages
- More elegant version of overlays
- Can talk to one page at a time
- Not every process actually uses that much memory (4GB)
- There is a core set of VPs (virtual pages) that a process is always using
- OS tries to keep these “hot” VPs in primary memory
- but sometimes memory gets too full
Page Fault
- if not in primary memory it may be in other storage (backing storage -- i.e. disk)
- OS is able to multiplex between resources
- What if you run out of space in primary memory and disk?
- then you’re in trouble
- memory requests for processes fail
- Solution: pick process to kill and reclaim space
- do this using a set of heuristics
- SWAP
- get more memory
Linux OOM Killer
- all available memory may be exhausted
- no process can make progress (and therefore free up frames)
- notice that it is out of memory
- select
- kill
How OOM picks its victim
- should NOT be:
- a process owned by root (init) 0, 1 kernel thread
- directly access hardware
- not be long-running
- should be:
- have lots of pages to reclaim (+children)
- possibly low static priority
Week 5
Oct 7: Page Replacement
Memory Management Recap
- PAS: how does the kernel support the ABI memory abstraction?
- virtual construct that an s makes available to every process on the machine
- not just 0-N collection that map to specific parts of a process
- provides a sense of isolation and protection for applications and programs
- how do you find stuff?
- memory addresses
- need a way to look things up
- OS gets involved to maintain idea of independent PAS
- Memory Addressing: why doesn't programs’ manipulation of variables conflict/collide?
- Virtual Memory: how does a kernel keep all processes in memory at once?
- Entry on segmentation and paging diagram
- every entry has a different format
- MMU as a function
- instruction has been decode
- CPU begins executing
- need to know where to write things to in memory
- e.g. mov 0x1234 0x1
- need to translate from logical address to physical address
- this is where MMU comes in
- logical address: ss:offest
- segment descriptor
- dpl bits
- does a privilege check
- actually translates logical to virtual address using segment descriptor
- takes virtual address and passes to page locations
- get a physical address
- checks for physical address validity
- what is cpl
- 2 bits, save on control register in CPU
- what if another process accesses the same virtual address as another
- physical addresses are made invalid
Bits:Contents of Page Table Entries
[ Diagram TBA ]
Page Replacement Focus Question
- How do you select which page frame to evict in favor of an incomming (from disk) memory page?
- RAM has a limited number of page frames
- Virtual memory allows us to expand this mapping to other devices (i.e. disk drive)
- Recall Picking a Destination Frame
- Dirty bit was this page written?
- Accessed bit: hardware sets this; OS must unset
- used to determine candidates for swapping
| Type of Approach | Simple Approach | Best Approach (Optimal) | Simple Approach (FIFO) | Second Chance (Improve FIFO) | Good Approach |
|---|---|---|---|---|---|
| Approach | select a random frame to evict | select frame that will be referenced furthest in the future (can compare instances of other approaches to it) | evict frame with "oldest" contents | evict in FIFO order, but check if page is in use before evicting | evict frame that has not been references for a long time |
| Pros | simple to implement and understand | optimal, maximally delays each page fault | simple to implement and understand, low overhead | vastly improves FIFO | semantics closely match optimal |
| Cons | may select a heavily-used frame, will cause a page fault | fantasy | may select an important frame (just because it was referenced a long time ago doesn't make it unimportant, use priority key) | degenerates to FIFO, shuffles pages on list | costly implementation; hardware requirements |
| Question | can we measure this? how bad is it in practice? | Might this be on a test (may or may not see a comparison on a test) | Can we improve FIFO’s knowledge of page frame content semantics | Note: mostly equivalent to “clock” (clock doesn’t shuffle pages around a list); relies on hardware providing a “referenced” bit | Can we avoid the need for updating the linked list? Or specialize hardware? |
LRU Page Replacement
- 4 physical page frames
- Memory reference string
- most page replacement applications are models
Oct 9: Recap
Test 1
- Results will be posted on SVN by tomorrow
- Encouraged to contact Dr. Locasto and TA’s more to clarify things
- Tests can be picked up from Dr. Locasto’s office during office hours or appointment time -- happy to discuss things
Assignment 2
- Are mostly programming questions
- kernel level programming problems
- Problem 1 - user level
- understanding of manipulating PAS in memory regions
- dependent on the set of system calls you use (HINT)
- Problem 2
- point of the questions is to get you looking in the right direction
- have access to linux source code -- use it (HINT)
- not sure how to do something? how does someone else do it?
- asks to profile location of stack (done in different ways)
- Problem 3 - MEAT of the assignemtn
- modify code in kernel
- extend basic functionality of kernel
- implement a new mode
- MOS - Robert Love’s text book (good resource)
- Question: How much of the asigment can we do now?
- question 1 you can easily do
- question 2 certain parts
- question 3 is learning exercise
- Question: How detailed should the man pages be?
- expected to go to the web to find out how to do this
- forces you to do documentation
Question Exercise
- 1. If we didn’t have computers, would we still need operating systems?
- Politics
- what is the relation between politics and OS
- set of resources
- social programs/law
- multiplex these resources and programs to maximize value
- Users don’t need details of details of subsystems (in society)
- Need concepts to manage resources
- Industry (Company)
- CEO group needs to manage workers (abstraction)
- files, documentations for different projects (data protection files)
- Libraries
- work as multiuser book OS
- allocating resources
- 2. What is the difference between:
- protected mode
- kernel space
- supervisor mode
- root user ?
- Do root’s processes run in ring 0?
- Protected mode
- Architecture mode (i.e. a mode the CPU can be in), is one of several modes
- when architecture starts up it is in real mode (no memory protection)
- switches to protected mode
- supports isolation between process address space
- Kernel Space
- space where the kernel dwells
- resides in same virtual address space as user level
- but the “line” separation exists
- virtual address space that is still distinct from user land via DPL bits
- is kernel replicated for each process?
- no, it just is
- keeps track of processes via task_structs/mm_struct
- there is a list that contains meta data
- kernel also needs pages (keep its code and data in physical space
- Supervisor Mode
- what is it’s relationship with protected mode
- certain instructions are not available if running in greater then ring 0
- have access to privilege instructions
- runs at ring 0
- Root User
- is a user account (super user)
- distinction? Does root’s processes run in ring 0?
- processes normally don’t run in ring 0
- do not run in ring 0, like any other user level process
- use system calls
- kernel will normally make an exception for it (unlike with normal users)
- can invoke certain system calls
- root’s program normally runs in ring 3
What’s in the Kernel?
- data
- task list
- task_struct
- process control block
- structure that describes the memory regions
- GDT
- IDT
- interrupt vector
- pointers
- that point to functions in kernel code
- one of the functions implements system call dispatch
- Syscall table
- maps syscall ids to functions
- drivers
- code
- functions
- schedulers (functions)
Could be ask to list what is in the code and data sections of the kernel and their relationships.
Oct 11: User-Level Memory Management
User Level Memory Management
- 1. The API
- 2. Algorithms (and data structures) for this space
The Problem:
- Support growing and shrinking memory allocations
- Solutions:
- First-fit
- Next-fit
- Best-fit
- Worst-fit
- ?
The API
- malloc - allocate memory (see man pages)
- free - gives back/freesup memory
- willing to adjust process address space
- what part of PAS is responsible for holding dynamically allocated memory
- heap - grows towards 0 (relative in the way of up or down)
- free - give back memory (see man pages
- fails if theres not more memory to allocate -- reason why should always checks malloc’s return
- e.g. malloc exercise (code on wiki)
- struct node* link - 4bytes (address pointer)
- can find the size of a data structure using sizeof(data_struct)
- why does struct node have 12 bytes?
- OS likes to deal with memory in terms of pages
- there’s a disconnect between OS and malloc
- addresses are somewhere in heap
- how do you know?
- ps aux | grep llist
- pmap PID_of_llist
- car /proc/PID_of_llist/maps
- strace -o llist.strace -e trace=mmap2.brk ./llsit
- look at what it does in terms of system calls
- tail -f llist.strace
- you can malloc as much as you want, OS does not get involved
- where does malloc get is memory?
- its not increasing heap
- malloc doesn’t directly manipulate heap
- will invoke mmap to ask for more memory pages
- does its own internal memory management
- at this point malloc does not need OS to increase the size of the heap
- allocating 12 bytes shouldn’t be something the OS worries about
Problem
- want to be able to grow or shrink in variable size chunks
Solutions
- 1. First-fit
- always go to the first available space form beginning
- 2. Next-fit
- keep track of the end of last allocated memory space and allocate from there
- start where you left off
- 3. Best-fit
- depends on memory request size
- looks at all holes and checks for the tightest fight
- takes more time
- 4. Worst-fit
- don’t care about finding best-fit
- greedy approach
- look at holes and fit itself into the biggest one
Problems with these?
- best-fit takes more time, same for worst-fit
- listening to user
- they’re asking for awkward chunks of memory sizes
- two problems from this kind of resource allocation
- Internal Fragmentation
- External Fragmentation
- hard to satisfy memory requests becuase of awkward chunk sizes, even if in total you may have a large amount of memory available (you can have many chunk of only 10 bytes)
- could split available resources into small, medium large
- problem: could exhaust a particular chunk, such as the large, will reject any further requests even though there may be space in the small and medium chunks
- memory managers makes it easier to deal with fragments
brk System Call
- Using source code on LXR
- sys_brk
- txt location
- uses macro to map to the actually brk system call
Week 6 [Scribe 3 Away On A Conference, Please refer to Scribes 1 & 2 for Notes]
Oct 14: No Class
No class Oct 14 (Canadian Thanksgiving)
Oct 16: Kernel Memory Management
Oct 18: System Startup
Week 7
Oct 21: Operating System Startup
Starting up VM
- GNU Grub
- small program that runs
- provides a menu to select OS you want to use
- can select any as long as grub knows about it
- When you pick a kernel
- OS is already running
- initializing a number of services
- creating and running user level services
- looks like booting but its actually not
- What happens between the time when you select a kernel and time you see the first output?
- Q: Why is startup “interesting”
- technical details
- conceptually
- going from sequential execution to concurrent execution
- A: Reveals (1) transition from sequential to concurrent execution (2) the interesting technical challenge of “bootstrapping” and fundamental OS job of hardware initialization
- So how does it actually do this? How does it go from sequential to concurrent?
- Concept of CPU multiplexing
- virtual CPU → process
- Startup provides a bridge between concepts
- between low level hardware events
- Startup involves taking hardware that is in an unknown state and imposing enough order on it that the kernel can run (and spawn userspace processes)
- Need to get it into a known state, a usable state
- get hardware in a state so that it can run the code
- Q: But how can a CPU w/o an OS actually execute anything?
- A: bootstrapping → relationship chain between ROM, BIOS, bootloader and kernel startup code
Startup overview
- 1. Initial startup program in ROM
- a) hardware reset
- b) load BIOS
- 2. BIOS Program
- a) initialize devices
- b) Txfr ctrl to bootloader
- 3. Bootloader (LILO, Grub)
- a) choose OS, boot options
- b) transfer control to kernel load rtn
- minimal amount of work is done to get to the next step
Setting Up the Execution Environment
- 1. Initialize hardware
- don’t trust BIOS results (written long ago)
- 2. Prepare interrupt table an GDT
- 3. Create OS data structures
- 4. Initialize core OS modules
- i.e. scheduler, memory manager, etc.
- 5. Enable interrupts
- implication, until now been excuting without interrupts
- critical phase, don’t want to be interrupt when for example setting up key data structures
- kernel does not have ability to multi-task, up until this point
- 6. Create null process (i.e. swapper)
- details vary depending on OS
- this does nothing
- sole role is to be present in scheduling
- 7. Create init process
- need to map code that handles particular things to appropriate interrupts
- GDT describes internal memory organization
- at the end of the above startup phase, concurrency becomes available
- Due to null and init processes you transition from sequential to concurrent execution
- note that even without the null and init process, you can have concurrency thanks to interrupts
- you want to make sure that everything is initialized and set up properly
- if interrupt happens during a key point during startup, you can leave the execution, but how do you go back?
- you don’t want that to happen
Linux startup Code Chain
- bootloader finishes executing and jumps to a known address
- at address is a setup function
- kernel_thread
- creates kernel process
- init, first program executed
- boot.txt in Linux Documentation (lxr)
- can use this if you want to write your own
- main
- starts in real address mode, jumps to protected mode
- protected mode
- sets up IDT and GDT
- Setup IDT
- setup GDT
- set up memory space and segments
- setup kernel data segments
- startup 32 entry point
- compressed kernel code, but CPU can’t process this
- this function uncompresses these
- eventually gets to initial code to start kernel
- start kernel
- set up scheduler
- shows a bunch of kernel functionality (see lxr, read through it)
- rest_init
- does the rest of initialization
- creates kernel thread (lives in kernel space)
- kernel init
- invokes init_post
- init_post
- kernel boot code
- process is responsible for running kernel_init which runs this
- the newly created kernel process attempts to run (i.e., execve) exactly one of these programs, trying them in order:
- /sbin/init
- /etc/init
- /bin/init
- /bin/sh
- run init process
- kernel_execve
- invokes execve system call
- /etc/rc.d/init.d/
- list of user level functionality that further sets up machine
- these are initialized after kernel is done setup itself
Oct 23: Assignment Review and Hints
- What have we talked about so far this term?
- What is OS?
- What is a process?
- Kernel
- roles
- illusion of unlimited CPU/Memory
- Memory management (user, kernel)
- internal/external fragmentation
- Virtual Memory
- System Calls
- Paging
- Protection
- isolation
- system architectural support
- Auxiliary
- Where to look for info
- wiki
- man pages
- How does lecture stuff relate to homework stuff?
- approach
Assignment 1
- 1. Problem 1 (man pages)
- knowing where to find stuff
- using man pages
- 2. Problem 2
- exposure to log messages
- become aware
- 3. Problem 3
- exposure to Kernel elements
Assignment 2
- each one is connected to the list of concepts above
- 1. Problem 1
- mmap system call is what you want
- understand how to create memory area at run time with certain permissions (readable, executable) that can store code
- demonstrate system call conventions in x86
- hex editor → lex
- write ← not recommended
- getpid, etc.
- 2. Problem 2
- point: what do you about how the OS keeps track of the memory regions
- /proc/PID/maps ← show memory regions
- not an actual file system, virtual file system
- point: where do you find info?
- using lxr (part 1)
- fs, documentation ← directories in linux
- data structures that keep track of memory regions (“memory regions as Linux defines them”) (part 2)
- vm area struct (contains mmstruct)
- /proc/PID/maps (part 3)
- posted on piazza
- 3. Problem 3
- add a system call to the kernel (tutorial exercises) that has a particular signature and effect
- effect is to mark (in a POD) a process
Oct 25: Process Scheduling
System Startup
- how to go from sequential to concurrent procedure
- give scheduler to process in order for them to operate
- does it through standard system calls
- How do you make a decision with which process to run?
The “problem” of scheduling
- As more processes are created, and some hundreds or thousands of processes come to exist, how does the OS choose which process should be given to the CPU?
- Suggestions:
- Pick at random
- First come first serve
- Priority/Urgency/Favorites
- Estimate of Workload, most work last
- Alphabetically (some arbitrary order)
- Save history of service
- work on near complete
- progress on incomplete
- Equal slots (Round Robin)
Scheduling is a mechanism that creates the illusion of simultaneous execution of multiple processes
Considerations for Scheduling
- Progress
- number one consideration
- goal of scheduler is take tasks and make sure that they all make progress (all relative to other metrics)
- Fairness
- Priority
- Efficiency (of scheduler)
- tightly related to the goal of the scheduler
- Quantum
- Preemption
Scheduling Metrics?
- Time
- Work type
- Responsive (delay)
- Consistent (delay variance)
- How do you balance time given to work on something versus the time it would actually take to finish a certain task?
Quantum
- The default amount of time given to processes to accomplish progress
- If too short, context switch overhead is high
- if too long, concurrency disappears
- my_stopped_time = N*quantum.length
- But does a long quantum make interactive applications unresponsive?
- No, these have relatively high priority, so they can preempt other processes
- allow programs to make significant progress
Preemption
- The kernel can interrupt a runnig process at any point in time or when its quantum expires
- Enables: “do something else more useful”
- Pre-emption does not imply suspension
- in Linux2.6 can happen either in user or kernel mode execution
Process List vs Run Queue
- list of all processes logically distinct from data structure used to organize processes into groups ready to be scheduled
- concepts are different, but implementations may share a data structure or be two completely separate lists
Priority
- different approaches calculate different absolute or relative priorities for the collection of runnable processes
- Which is important to run now?
- FCFS, Round Robin, Workload size → concept of priority
- man nice
- user level utility that allows you to affect priority of a process
- nice value is a parameter that goes into consideration for assigning priority to process
Types of Processes (see slides)
- Traditional Classification
- Alternative Classification
- Orthogonal consideration
- interactive?
- critical? (i.e. deadlines)
Orthogonal
- A batch process can be I/O bound or CPU bound
- Real time programs are explicitly labeled as such
- Interactive vs batch
Conflicting Objectives
- Fast response time (processes seem responsive)
- Good throughput for background processes
- Avoiding “starvation”
- make sure all programs are making progress
- Scheduling policy: rules for balancing these needs and helping decide what task gets CPU
- FCFS: but all come at same time, pick one
- pick A (based on work?), runs at 3 units of time
- if process finishes early, extra time, call scheduler pick the next proces to run
- note: quantum will only mean something in round-robin approach
- need to account for context switch
- context switch: swapping between process (saving register and prepping for next process)
Week 8
Oct 28: Process Scheduling Con't
Scheduling Algorithms
- 1. FCFS
- arbitrary order on who gets there first
- implication is that a process will run till it’s done
- 2. Shortest Job Next
- high responsiveness
- processes that have lots of work to do constantly get shafted to the end
- 3. Round-robin
- equal time slice (quantum)
Policy vs Mechanism
- scheduler structure
- other areas:
- mem management
- disk
- other resources
- two parts
- 1. data structures
- 2. part that manages which task is next
- Mechanism → which process runs next
- Policy → drives mechanism
- Recall Process Lifecycle
- How do you know if the approach is good/appropriate?
- Meaningful metrics?
- Can track when a process “arrives” and when it starts to run
- Wait time
- progress? being able to finish the work?
- Turn around time (difference: time of arrival to completion time)
- Can take the average time, and judge
- want relatively low average times
Linux Support for Scheduling
- flags for scheduling policy
- support multiple approaches to scheduling
- breakdowns (linux has support for both)
- normal scheduling
- real time scheduling
- FIFO
- FIFO, RR (round-robin) get more priority → OS is programmed this way
- non-real time setting
- not FIFO, not RR, not Shortest job next
Linux 2.4 Scheduler
- schedule() function
- called by OS when it needs to make a scheduling decision
- scheduler (repeat_shcedule)
- swappable (process 0) → process that’s always runnable
- list_foreach
- every cpu has a runqueue (set of runnable processes)
- checks if process is runnable
- goodness (priority)
- Order n scheduler
- Non-RT Process
- normal case first
- checks if process is the currently running process (won’t have to switch in memory
- Efficiency → minimize cost
- How do we avoid iterating over n processes to pick the best one?
- some sort of priority queue
- use data structures instead
- 2.4 Scheduler is okay, but costly
Linux 2.6 Scheduler
- Order(1)
- predictable length of time
- cheaper algorithm
- point scheduler ot next task
- work amortized elsewhere
- OS constantly going in and out of user and kernerl
- maintaining multi-level feedback
- needs to consider if there are any real time processes first
- every CPU has run queue
- each queue has fields that point to arrays
- one array is the active set of processes (processes that have not had the chance to run)
- the other are expired processes (have already had the chance to run)
- next task is simply the 0th entry in the active set
- each array is 140 in length
- this is a for loop but why not O(n)
- there’s only 140
- size is not unbound
- RR
- as number of processes grows
- this is a policy, not a mechanism
- informs calculations
- maps well to mechanism
Context Switch
- takes care of switch meta data
- assembly code that switches state of stack
- happens when switching from current process to next
Oct 30: Concurrency, Communication and Synchronization
Concurrency
- OS goes to great lengths to achieve this
- comes at a price!
- Interprocess Communication (IPC) → the killer app for techniques that manage concurrent execution
Concepts
- Race Conditions
- situations where two or more tasks compete to update some shared or global state; such situations cause the final output to depend on the happenstance ordering of the tasks running rather than a semantically correct computation
- defines results that you get
Critical Sections
- are a name for code regions or slices that contain instructions that access a shared resource (typically sharing some type of memory or variable)
- (1) a code location or sequence of instructions
- (2) an environment and set of conditions
- defined by seven operations
- defined not by the instructions involved but by the shared state
- code that manipulate shared state
- is the data involved in the sequence of instruction potential manipulated by the sequence of instruction
- can multiple threads be in the same shared state?
Mutual Exclusion
- fundamental idea
- concept that states only a single task should have access to a critical region at a time; enforcing mutual exclusion helps serialize and normalize access to critical regions and the memory, data or state that code of a critical region reads and writes
- only exactly one thread/task in a critical section at one time
- don’t want multiple threads to have access to a critical section
- once a thread/task is done (falls out) then another thread/tasks has a chance to work in the critical section
Classical IPC Problems
- 1. Producer-Consumer
- 2. Dining Philosophers
- 3. Readers-Writers
- history | grep “awk”
- output of history gets fed through shared pipe then into grep
- Shell I/O redirection
- command line pipes
- named pipes
- Concurrency introduces a problem and need to be able to handle this otherwise output is incorrect
Example
- thread1 and thread 2
- How would you create two threads and have them execute at the same time
- fork()
- second process executes code as soon as fork returns
- two process running exactly the same code
- is there a concurrency problem
- each process has own PAS
- no conflict, no critical section
- clone()
- creates another thread of control that executes in the same process address space as the process that called it
- there would be a critical section
- multiple controls try to access this section
- thinking of critical section not as a series of code but as something that manipulates shared state
- one thread could be producing and the other consuming → two different sets of code but there is a critical section because they both have a shared state that they are manipulating
Potential Solutions
- lock variables (recursive problems)
- not good because in essence two threads/tasks could still be access the same global variable in the shared state
- disabling interrupts (not trustworthy, multi-CPU systems unaffected)
- sounds good but why is this not good?
- spin locks (potential solution if done correctly) -- (feasible but usually wasteful because CPS is busy doing “nothing”)
- sets “not_allowed”
Nov 1: Deadlock
Announcements/Reminders:
- 1. Test on Wednesday
- 2. Assignment due Friday
Deadlock
- system is essentially dead
- processes cannot make progress
- resources are “on hold”
Seeds of the problem (see slides)
- safe concurrent access requires mutual exclusion
- danger: not just one resource available and requires protection
- many jobs that map to many resources → who to give access to resources?
- to avoid deadlock → careful programming
- The order in which resources are access may lead to deadlock
- e.x. Process 1 has resources 1 and 2
- Process 2 tries to gain access to 1
- it doesn’t get access to it -- Process 1 already has a lock on it
- once P1 is done, P2 can access the resources it needs
Resource Deadlock Definition
- two or more processes are blocked waiting for access to the same set of resources in such a way that none can make progress
Conditions Necessary for Deadlock
- 1. Mutual Exclusion: Each resource is only available via a protected critical section (single task)
- don’t have this, no deadlock
- unsafe concurrent access
- 2. Hold and Wait: task holding resources can request others
- 3. Circular Waiting: Must have two or more tasks depending on each other
- must have dependency
- 4. No Preemption: Tasks (responsibility) must release resources
- These four conditions have to hold in order for deadlock to occur. Deadlock is still likely to happen though, even without all four present.
- Deadlock is a Manufactured Problem
- i.e. try to fix one problem, but solution actually gives rise to deadlock
- Resources are usually locks in this context
An approach to preventing deadlock:
- note: read in text (hint: might be useful for test)
- carry out a sequence of resource requests
- update the resource graph with the corresponding edge
- if there’s an edge from a process to a resource then process is trying to gain access to a resource
- edge from resource to process then process has access to that resource
- check if graph contains a cycle
- detecting deadlock
Approaches to Handling Deadlock
- 1. Avoidance
- ignore it
- implement dynamic avoidance (e.g. speculative execution, resource graphs) approach to inform resource allocation
- check each request
- 2. Action
- let deadlock happen; detect this and attempt to recover
- prevent it from happening in the first place (usually by scrupulous coding); attempt to make one of the four deadlock conditions impossible or untrue
Recovery Tactics
- 1. Preemption: suspend & steal. Depends on resource semantics
- not a solution → approach
- 2. Rollback: checkpoint & restart. Select a task to rollback, thereby releasing its held resource(s)
- 3. Terminate: (1) break cycle (2) make extra resources available
Deadlock Avoidance
Banker’s Algorithm (not tested)
- The art of abstraction hinders the application to reality
- need to know max resource request
- physical devices break
- number of new tasks hard to predict
Program Structure
- Introduce sequential processing (avoid mutual exclusion)
- safer than concurrency, but lose all the benefits of concurrency
- touch to break hold and wait (prediction)
- no preemption
- touch to kill or preempt due to reliance on semantics and data correctness
- circular wait
- sequentially enumerate resources
- impose (code) rule of sequential access
- dependency (essence of deadlock)
Causing deadlock with pthreads (with code)
- user level threading line
- library that provides illusion to threading (no system calls needed)
- Code on the wiki
- into to pthread api
- start up two threads which access two variables that they can access safely
- access resources change values
- can run this program as many times as you want
- conditions are present
- threads are not their real creators → simulators
- in order to expose deadlock
- without delay, scheduler just picks
- by introducing delay to first thread will allow others to run
- Writing a threading program (tie.c)
- global vars, pthread types int types
- threads are represented and accessed through p1 ans p2
- most data structures have mutex embedded
- mm_struct
- first initialize mutex
- allows code to use it appropriately
- create the threads (order doesn’t matter, can have an array, linked list, etc.)
- use pthread_create
- pthread library calls mmap
- keeps track of stack → constnant contact
- nice to use pthread_create’s return value (0 or -1) to check if the thread was actually successfully created
- two different jobs
- can have the same pointer
- two different src codes that share the same work space
- have critical sections
- pthread_join
- joins two threads
- do_some_job
- in here is the critical state → shared space
- locked the boxes in differnt order
- the order in which you do things is essentially what you, as a programmer, have control order
- screwing up the order introduces the problem of circular wait
Week 9
Nov 4: Kernel Synchronization
Recap
- Defining a critical section
- How big should a critical section be?
- want it to be as small as possible, but don’t want a lot of them
- When and where should a critical section be imposed?
- What should it contain?
Kernel Synchronization
- kernel’s are
- naturally concurrent
- servicing interrupts, requests, etc
- kernel has do synchronization
- how does the kernel implement this
- how does it deal with safe concurrent access
Kernel Control Flow
- Complicated
- natural asynchronous
- How can the kernel correctly service requests?
- any function can be executing at any given time
- have multiple control paths at some state doing interleaves
Main Ideas/Concepts
- 1. Atomic operations in x86
- how tied to the hardware safe concurrency is
- 2. Kernel locking/synchronization primitives
- what are these primitives
- 3. Kernel preemption
- kernel can preempt a running process (we’ve seen this already)
- i.e. suspend one process and let another run
- kernel can preempt itself
- 4. Ready-copy-update
- 5.The “big kernel lock”
- early days → only one mutex
- forcing/correcting concurrency
- going from coarse grained concurrency to fine grained concurrency
I. Synchronization Primitives
- Atomic Operations
- CPUs can do things in a signle cycle
- have ways to force this
- Disable Interrupts (cli/sti modify IF of eflags)
- another way to get synchronization
- on a CPU basis
- Lock memory bus (x86 lock prefix)
- enforces system synchronization
- Spin Locks
- Semaphores**
- more “graceful” spin locks
- knowing when to use a semaphore or a mutex ← important, good skill
- Read-Copy-Update (RCU -- lock free)
- Barriers
- accumulates
Example: Using Semaphores in the Kernel
- down_read, up_read and mmap_sem
- uses part of the api that manipulates semaphores
- down_read and up_read → useful for HW2 problem 2
- down_read
- marks where the critical section starts
- signal that it will perform read operation in the critical section
- there is a corresponding down_write
- most locking is advisory locking → this is totally “voluntary”
- most data structures have appropriate locking and unlocking primitives
- current->mmap->mmap_sem
- in struct mm_struct: include/linux/mm_types.h
- have fields that help keep track of meta data (e.x. mm_users, mmap_sem, page_table_lock)
- On x86 these operations are atomic (see slides)
- simple asm instructions that involve 0 or 1 aligned memory access
- read-modify-update
- atomic_t: include/linux/types.h
- static inline void → right in the code
- asm volatile → translates to machine code
- force manipulation
- simply declaring an atomic type is not enough, need to actually invoke it
II. Spinlock Primitives
- /include/linux/spinlock_types.h → look at LXR definition
- they are a generic locking API
- arch/x86/include/asm/spinklock_types.h
- int that gets modified
- mutex, flag
- spinlock API
- locking is expensive
- makes it as cheap as possible
- delegate down until you get the appropriate primitive
- /include/linux/spinlock_api_smp.h
- want to disable preemption of kernel
- don’t want any interruptions
- barrier synchronizes memory bus
- LOCK_CONTENDED → macro, should lock the whole thing, has function pointers
- eventually calling do_raw_spin_trylock
- there’s machine code that is specific to the architecture
- architecture is the foundation
III. Semaphores Primitives
- mainly consider Read/Write Semaphores
- can have multiple readers in a critical section
- but want to be careful with writers
- rw_semaphore
- semaphores are NOT spin locks
- variables
- count → counting mutex; counting how many threads can enter the critical section
- wait_lock
- is concerned with the wait_list not so much the semaphore
wait_list
- protected by a spin lock
- critical piece of a critical shared state
- will require a lock in order to put things on the wait list
- QUESTION: why is it a linked list and not a queue (FIFO)
- this pertains to a scheduling problem
- might_sleep()
- calls schedule
- thread might be put to sleep
- Consider what happens when something exits the critical section
- need to decide who gets to enter critical section next
- up_read, up_write
- rw_sem_wake
- kernel
- if there is a writer at the front of the queue then the get access (checks for writer first)
RCU (see slides)
- What does it do
- treats reader and writers the same way (initially)
Big Kernel Lock
- basically a spin lock
Nov 8: Threads (User Level)
GDB
- Let’s you recover context at the point program crashes
Looking at Code [| pc.c]
gdb -q ./<executable> [runs gdb]
In GDB
disassemble <function inside program>
- expands/disassembles this chunk of code
break *<address>
- break point at given address
run code
- runs code
- will shows all sorts of information
i r
- info on registers
- can be: info reg
stepi
- step one instruction
x/16i $eip
x/16x $eip
- can examine as set of instructions or as hex, respectively
Producer/Consumer Synchronization
- start with a couple of threads
- share access to integer buffer
- producer will generate an integer at a time and inserting to the buffer
- consumer reads from the buffer and deletes entries
- Why doesn’t x need to be protected by a lock?
- there is only one thread accessing x (producer)
- no actual concurrency going on
- Inside critical section, calling a bunch of functions; good or bad decision? (Looking at produce function in given code)
- poor style? -- a lot of work in these function calls
- Key question: too much work, too little or just enough?
- what justification do these functions have for being in the critical section? Are they manipulating the shared space?
- if the are manipulating or access this shared state, then yes they need to be in the critical section (in the case of this code it will be the producer and consumer reading/inserting into the buffer)
- justified in that it needs to do its work inside the same block
- if something is not needed, it doesn’t need to be in the critical section (in the case of the code, it is the if statement in the produce function)
- Without sleep, lets threads run as fast as possible, changes frequency and order producer and consumer do their thing
- play around with the code
- concurrency bugs are hard to find and reproduce
Week 10
Nov 11: Remembrance Day (no class)
Remembrance Day is 11 November. No class.
Nov 13: Signals
- Signals are a simple form of communicating
- OS support for generating and delivering signals
Signals
- useful but limited API to send short, pre-defined “messages” to process
- basically a number that is sent from one process to another
- signals may generated by
- user
- another process
- kernel
- why → process may have done something it shouldn’t
- provide a way to:
- notify a process that an event has occurred
- allow the process to run specific code in response to that event
- simple way of handling asynchronous event handling
- Looking at kill(1)
- sends a signal to a process in order to terminate or kill it and it wil do exactly that unless you do something different
Shell Demo
- w → shows which users are on the “network”
- ps aux | grep deys → lists processes
- man kill
- man signal(7)
- have different signal messages
- note: hw3, question 5 asks you to use SIGUSR1 & 2
- kill -9 8001 → -9 is the signal number, 8001 is the pid
- won’t work if not super user → privileged functionality
- provides protection from other users trying to kill your processes and vice versa
- hangup signal (SIGHUP) → nice signal to use, not as brute as kill
- Most processes have custom definitions for handling signals
- signals are not the primary means for communication even if they’re convenient and well-defined
- alternative to kill(1) that will allow for more privileged actions is by using a system call → kill(2)
Basic Signal Workflow
- 1. Signal s is generated
- 2. Kernel attempts signal delivery to current process (if target not current process, the signal is pending)
- 3. Else, kernel delivers signal to process
- 4. But process may have blocked this signal
- 5. Process may also be masking this signal
- 6. If delivered, execute default action or sig handler → number from signal is written somewhere in the task_struct
- Control Flow (Catching a signal) → get from slides
- Signal is not a normal messages → it is an exceptional condition
- Can we handle exceptional conditions better?
Case Study: ptrace(2) (Read man page)
- ptrace(2) enables one process to trace another (examine state, control execution,read/write memory
- offers interface to allow one process to talk to another using its pid
- purposely breaks isolation between process to allow for this tracing to happen
- it can give complete access to one process to another
- versatile but its weird in the privileges it opens up for processes
- PEEKTEXT and PEEKDATA are the same in Linux, because Linux doesn’t separate text and data address space
- might not want to use PTRACE_CONT, better to use PTRACE_SYSCALL, PTRACE_SINGLESTEP → gives you more control
- can examine every single instruction
- Taking a look at code:
Nov 15: Files and File I/O
Announcements
- USRI Dec 2
- Final Exam, Dec 18th 8-10AM ICT 102
Perspectives
- traverse a few layers of abstraction
- begin with a user-level tool-based manip
- C library functions and structures
- System call API
- set of perspectives to illustrate three diff ways to interact with file content
- have our experience mediated by software apps
- have our experience mediated by C library
- ask the kernel directly for service
Motivation/Focus
- How does the kernel provide support for managing persistent data?
- The “file” abstraction
- Everything in Unix is a file
- Questions to consider
- how to find a file?
- how to retrieve particular pieces/bytes of a files?
- handling duplicate files?
- handling multiple requests for the same file
- storage? where? in what order?
- indexing?
- access permission? who can read or write to the file? delete?
- manipulating subsets of files
- file quantity issues?
- MOOC?
- File Management systems
- responsible for making management efficient
- important to understand what existing FMS do
The Problem of Files
- Why do we need files?
- Virtual memory isn’t big enough
- useful data needs to persist beyond a power cycle (i.e. reboot)
- Concerns?
- persistent storage
- how to find a file?
- looks a lot like memory addressing
- asserting ownership and control of a file
- looks a lot like segmentation DPL and page protections
- how do you dynamically grow a file’s content
- memory allocation
- how do you keep “hot” data close to the CPU/registers (supporting performance in an efficient manner)
- virtual memory
File Content
- What is a file?
- data
- relationships between data/bytes/content
- “container”
- can be manipulated
- What is in a file?
- bytes/data
- address/identifier (how to locate a file)
- physical location
- bytes of content
- is an abstract or virtual container for data
- logically made up of a collection of (fix-sized) blocks
- can use hexdump to look at the raw content of a file
File Type
- extensions do not mean anything
- don’t want to see files just as a series of bytes
- binary programs have readable ASCII content
- Unix files contain pure data - not markup
- the file(1) command
- user utility
ELF from Scratch?
- Can we write an ELF from scratch?
File Attributes
- Unix files typically do not embed metadata about the file
- metadata is typically expressed via the type of file system the file resides on
File Permissions and Ownerships
- permissions → users and programs/processes
- Mandatory Access Control (MAC)
- Discretionary Access Control (DAC)
- owner of file has the discretion to allow or not allow access to that file
- command line: ll
- 1st col: describes permissions (read write execute)
- d → directory
- file/dir-user-group-other (given permissions)
- e.g. -rwxr-xw---. (drwxrwxrwx. → the entire thing)
- it is a file
- user can read, write and execute
- group can read and execute
- others can write
- 3rd and 4th: ownership (user & group (which is a collection of users))
- command line: chmod
- can change permissions
- e.g. chmod 555 <file>
Week 11
Nov 18: File Systems Overview
Nov 20: The Linux VFS
- How does the OS manage persistent data?
Today
- How different files systems are supported by linux?
Virtual File System (VFS)
- interface sits right on below Linux’s implementation of the file I/O API
- trace from user level interface (command line utilities) to VFS and how it manages things
- e.g. echo “Portlandia” > file.txt & cat file.txt
- there is C code behind this
- take: cat file.txt
- → fopen()
- → open(“path”, flag, node) = fd
- path is the file
- flag - R/W
- node permissions
- recall that there is a distinction between directory tree and file map
Fig.1
[ file related system calls: open | read | write | … ] [ VFS ] → sits under the file system API → EXT 2/3/4 → BLOCK I/O
→ hardware
- VFS, see Fig 1
- if VFS didn’t exist, you’d have to worry about a lot of specifics such as devices to read or write
- would result in a messy and bug filled API
- VFS is an internal API for the kernel
- system call API can use VFS, which supports file related system calls
- file related system calls delegates to VFS calls
- VFS needed for behind the scenes work (things that the kernel cares about, such as where bytes and things are actually stored → things that we don’t want to worry about at the user level)
- 7 layers of calls
- command line utility
- corresponding C code (fopen)
- system call (open)
- file I/O API
- VFS API
- extensions/data structures
- Block I/O
- memory/disk drive/Network
Recall inode
- What is an inode
- part of a kernel data structure that contains the handler or pointer (meta data → reference) to a file
- allows OS to reference a file
- different versions of inode
- generic
- when you open a file an inode instance is created
- EXT4 inode
- iblock[EXT4_N_BLOCKS]
- array of pointers to blocks
- allows for addressing/indexing a file
- NOT in the generic inode
Looking at Open, Read and Close System Call
- Take a look at LXR documentation
- helper routine/function call → do_sys_open
- creating a mapping with the struct file and fd (file descriptor)
- fd_install
- struct file describes the state of this file
- array is a collection of data structures that contain meta data
- do_filp_open
- this is where all the work is done → where data structures, etc. talks to physical devices such as drivers and memory
- VFS_read
- in the system call layer and have delegated to the VFS layer
- VFS layer will help identify where the file is, where bytes are stored, etc.
- do_sync_read
- do_generic_file_read - reading from caches (file data) → final delegation to hardware
- Kernel is doing asynchronous IO
- slow compared to CPU
- Block layer → store chunks in memory
Nov 22: Extended Attributes in Ext4
Week 12
Nov 25: Example File Systems
Minimally Viable File System
- How do you do this?
- Assume you have a well behave storage system
- provides some units of storage space (0-max)
- What are we supporting
- open, read write, seek, close
- unlock
Design Requirement
- delete
- expand file
fd = open(“one”); write(“data”, fd);
[ one | two | … | five | ] 0 max
- What happens when we want to add a byte of data to file two?
- add a new “partition”/offset somewhere and have a pointer pointing to it from the previous part? → there’s a problem
- have a bunch of metadata → tracking where each set of bytes for files stored, how big, etc.
- Modification of Min File System
- start of file
- where subsequent byte file is located
Block → fixed size
File Allocation Table (FAT)
- have a table at the beginning of the disk that describes where files are, where byte file is etc.
- have to store table in memory
- What is a file?
- What restrictions does it have?
- EXT 2/3/4
- given some inode → recovers the location of the rest of the file
- How many blocks to allocate to a file?
- consider behaviour of system
- files tend to expand
- Managing blocks
- what happens when it grows beyond 8 blocks?
- becomes highly fragmented
- EXT 2 tries to keep data and files relatively close
Journaling Filesystem
- log data and metadata operations
- log metadata operations
- log metadata
Nov 27: Device and Device I/O
Overview
- I/O devices main means of interaction between users and CPU and Memory
- Main design Challenge: bridging the gap between user level program expectations and what the properties of low level hardware are
Topics
- character devices
- block devices
- major/minor numbers
- mknod(1), mknod(2)
- mkdir, mkfifo
- special devices (pipes, FIFOs, etc.)
- pseudo devices (/dev/null, /dev/zero)
- /dev/null → “garbage can”
- file name/location in file system
- operationally its a sink/output we don’t care to maintain
- echo “bye” > /dev/null → redirected to /dev/null which is “thrown away”
- chunk of code that mimics function of a device
- udev; dynamic device registration
- I/O transfer / BUS
- memory mapped I/O
- DMA
- interrupts vs polling
- man 3 makedev
Device I/O API
- devices are usually treated in the same way as files (looks like a file, named like file, but doesn’t behave like one)
- feels like using an actual file
Device Landscape
- device driver → part of the kernel dedicated to communicating with devices (is a pile of code)
- question: how does the device driver know how to interact or communicate with a particular device
- kernel needs extra code and data structures to manage this
- devices include some sort of hardware buffer (device controller → controller interface)
- device controller is driven by the device driver
- device controller (typically a processor attached to or embedded in the device) exposes a few control registers and a buffer to the kernel
- hardware device itself performs some real physical actions
- What is the CPU’s role in all this?
- managing execution (communications) of device driver with the device controller
- handling interrupts
- IDT (interrupt descriptor table) → CPU actually looks up what needs to happen and who needs to handle what the interrupt wants
- context switch
- asynchronous and event driven
Device Files
- every device registered on the machine has a corresponding file manager
- can mount a device: mount /dev/sdb /media/space
Device I/O API: Device “Types”
- Devices are typically viewed, accessed, and controlled as either
- block device → data is accessed a block at a time; random access
- character device → a stream of characters (or data values)
Major/Minor Numbers
- uses major and minor numbers to create files that represent each device in order for the kernel to known which driver should aid communication with the device; kernel needs to map drivers to device files
- can see this using:
- stat
- cat /proc/self/maps
Example Driver
- 3COM 3c501 Driver (can find this on lxr)
- network device drivers
Communication
- Bus is the communications pathway
- devices in memory are attached to this
Nov 29: Mass-Storage Systems
Moving-head Disk Mechanism
- Goal of head of disk
- get data into right sector
- two motions
- read-write head of arm is on the right platter
- head is actually on the right sector
- Disk Scheduling
- OS responsible for efficient use of hardware (fast access, etc.)
- Seek time
- read-write head moving back and forward
- Rotational Latency
- getting to right sector through rotation
- Minimize seek time
- Disk bandwidth
- total number of bytes transfered
- Algorithms exist to schedule the servicing of disk I/O requests
- Illustrated by a request queue (0-199)
- e.g. 98, 183, 37, 122, 14, 124, 65, 67
- initial state of Head is at 53
FCFS
- first come first serve
- For example above
- start at 53 --> 98 --> 183 --> ...
- What's wrong with algorithm
- total head movement of 640 cylinders
- worst algorithm due to rotational latency
SSTF
- shortest seek time first
- For the example
- total head movement of 236 cylinders
- better in the sense of having longer access time
- obviously better than FCFS
SCAN
- scans the entire area (queue)
- for the example scans from 0-199 and back
- head movement of 236 cylinders
- so starts at 53 --> goes to number closest to 0 --> then proceeds in numerical order towards 199
- down side
- consider a dynamic system
- access to different cylinders are not uniform
C-SCAN
- circular scan
- scans from 0-199 but instead of scan back it just jumps to 0 again
- For example
- starts at 53 --> 65 --> 67 --> 98 --> 122 --> 124 --> 183 --> 14 -->
- 383 cylinders
CLOOK
- circular look
- similar to c scan but does go all the way to the beginning
- jumps to the left most value (saves movements especially if the left most value is not the beginning)
Selecting Disk Scheduling Algorithm
- SSTF
- common and appealing but...
- starvation problem
- SCAN and CSCAN
- good with heavy loaded disks but can have problems with bigger files
- Performance, dependent on requests (count, type)
- Requests for disk service influenced by file allocation method
- has an effect on performance (rotational latency)
- SSTF or LOOK
- reasonable default algorithms
- still depends on what needs to be done
- Disk Scheduling algorithm would benefit from being written as a separate module of the OS
- makes it easier to switch between different algorithms if need be
Week 13
Dec 2: Kernel Network Support
Dec 4: Network Support in Operating Systems
Network Support in Operating Systems
- 1. Communications endpoints, addressing
- 2. Reading from the network
- 3. Writing to the network
- All this is on the syscall layer + kernel network filtering architecture
- 1. netstat, ifconfig
- 2. wireshark/tcpdump
- 3. netcat (nc(1))
- - Netfilter as a means of customizing packet flow
ifconfig command
- inet addr: IP address
- identifier of layer 2: MAC address
Sockets
- OS supports these
- Sockets are numbered, up to 65,000 sockets available
- OS tracks which ports are open
- use netstat
- there are forms of sockets that are local
- netstat shows connections, local to foreign IP address
- port number is the “bridge” between outside sources and the local machine (allows for receiving and sending data)
- OS maintains binding of ports and maintains their state
Reading from the Network
- tcpdump
- tcpdump -i eth0 (needs to be run as root)
- wireshark
- captures packets
- see a range of bytes that have arrived to the network
- protocol, what it’s actually using to communicate (TCP, ARP, etc.)
- your information is actually broadcasted to any machine that cares to listen
- not as private as you would think
- implication: tcpdump asks for permission to read all the packets available in the network
- can be used for driver communication
netcat (nc)
- utility that allows you to establish connections to transfer/write data
- first thing kernel does is to look up the IP address it needs to connect to
- store IP address
- establish connection
- Initiating a connection involves a bunch of protocols
strace
- traces system calls
- can use this to trace only the system calls involved with the network
- more nc.out
- shows a list of all the system calls involved
- i.e. binding a socket/port, connection established -- port is listening/waiting,
Command Demo
- nc -l 9999
- bind to port
- can check that this succeed through nc -an | grep 9999
Dec 6: Final Exam Review
Concept Map
on the wiki - shows how things relate
Final Exam
- Multiple Choice
- 22 T/F first half
- 22 regular MC
- 1 Sheet of notes (back to back)
- can bring a calculator
- Recall/Trivia type questions
- Some questions with a bit of work
Content
- 1. File systems
- 2. Concurrency
- scheduling algorithms
- how to simulate
- turn around time
- problems in deadlock
- 3. Page replacement algorithms
- internal organization of synchronization primitives
- semantics, structure, etc.
- how a particular primitive may or may not apply to a given problem
- memory address translation
- separation between MMU and CPU and OS roles
- 4. Disk Scheduling
- know the algorithms
- modification of scheduler
- 5. Performance (as said on wiki) → won’t be too much focus on this though
- How in depth should we know about file systems
- 5 questions, some T/F
- concentrate ext 2,3,4, XFS → the ones talked about in class
- Questions from LXR?
- know how certain constructs are expressed