Courses/Computer Science/CPSC 457.F2014/Lecture Notes/Scribe1
The Computer Science 457 - Principles of Operating Systems course offered here at the University of Calgary is an undergraduate level introduction to computer operating systems. It covers modern OS implementation on commodity hardware with a curiosity-driven cross-layer approach. It uses Linux to help ground the discussion and material.[1]
Contents
- 1 Participation
- 2 Deadlines
- 3 Lectures
- 3.1 Week 1
- 3.2 Week 2
- 3.3 Week 3
- 3.3.1 Monday, September 22, 2014
- 3.3.1.1 Quick Overview
- 3.3.1.2 CPU: Central Processing Unit
- 3.3.1.3 Modes / Rings / States
- 3.3.1.4 The OS and the Hardware
- 3.3.1.5 Fundamental Flaw with Diagram
- 3.3.1.6 Kernel Code vs. User Level Code
- 3.3.1.7 Supervisor Environment for x86
- 3.3.1.8 Segments
- 3.3.1.9 Global Descriptor Table and the GDTR
- 3.3.1.10 Additional Notes from Class
- 3.3.2 Wednesday, September 24, 2014
- 3.3.3 Friday, September 26, 2014
- 3.3.1 Monday, September 22, 2014
- 3.4 Week 4
- 3.5 Week 5
- 3.6 Week 6
- 3.7 Week 7
- 3.7.1 Monday, October 20, 2014
- 3.7.2 Wednesday, October 22, 2014
- 3.7.2.1 Overview
- 3.7.2.2 Class Starter Exercise
- 3.7.2.3 Internal vs. External Fragmentation
- 3.7.2.4 External Fragmentation
- 3.7.2.5 Internal Fragmentation
- 3.7.2.6 Request for dynamically allocated memory
- 3.7.2.7 malloc
- 3.7.2.8 calloc
- 3.7.2.9 realloc
- 3.7.2.10 free
- 3.7.2.11 mmap
- 3.7.2.12 brk
- 3.7.2.13 glibc exploration by example
- 3.7.2.14 questions
- 3.7.3 Friday, October 24, 2014
- 3.8 Week 8
- 3.9 Week 9
- 3.9.1 Instructor Notes
- 3.9.2 Monday, November 3, 2014
- 3.9.3 Wednesday, November 5, 2014
- 3.9.4 Friday, November 7, 2014
- 3.10 Week 10
- 3.11 Week 11
- 3.12 Week 12
- 4 References
Participation
The beauty of a wiki oriented discussion platform for CPSC 457 is that it opens the floor to collaborative editing. Feel free to modify any information contained herein. This page has been created with the aim of helping fellow students enrolled in the course. Extended detail, beyond the scope of lecture presentation is provided, time permitting; this material is marked to alleviate any confusion students may have. If you feel as though you have anything you would like to add, modify, remove or update - by all means get intimate with the edit button.
Disclaimer
All information contained here-in is at the mercy of those who wish to contribute. With that in mind, we are not official staff and therefore everything should be taken with a grain of salt. As preached in lecture - consult authoritative sources when in doubt.

Deadlines
The following table is always being modified/updated (feel free to lend a hand)
Calendar
LecturesWeek 1Instructor NotesMonday, September 8, 2014Quick Overview
 Graph on left : Emerges out of what an Operating System is, how it operates, how it supports the existence of execution; basic organization. Middle graph : Concurrency - How do we create the illusion, how do we manage the problems that arise from achieving it. Graph on right : Memory files – general data, how do we manage data, how do we access, how do we protect it , how do we do this efficiently, how do we do it in a manner suitable to the underlying hardware we’re talking about. Professor Bio
Related Links
Wednesday, September 10, 2014Quick Overview
Operating System: Purpose"What we have here, is, failure to communicate"Operating Systems essentially mediate access to hardware - in other words they provide an environment for application level programs; software would be unable to do it's job if the Operating System was not there. The Operating System does two main things to aid in the communication with the hardware - You thought juggling two discrete relationships at once was hard ? Try 100+. "This is magic, this is mystery". One of these magical traits lies it its ability to manage time multiplexed resources (ie: CPU) and the second emerges from its crafty management of space multiplexed resources (ie: Hard Drive, Memory). In addition the Operating System has a knack for turning your code into a running process.
CPSC 457 Practical SkillsJames Sullivan (Scribe3) has written a nice list of the learning outcomes for the course. Check out his link - here. Introduction to the Command Line"Learning the command line is really just a matter of exposure and persistence. It helps to have a Unix-like environment as your primary desktop." 1K Linux CommandsWritten by Professor Michael E. Locasto, this resource offers an introduction to the command line. (Link)
Linux Commands (Illustrated)The following image gallery is meant to serve as illustration of the various commands introduced in lecture. The commands associated with this particular image gallery correspond to commands executed on a Linux Slackware VM Image - Linux Kernel 3.10.17 . The host operating system specifications can be viewed here.
Writing our C program (math.c)The code int main(int argc, char* argv[])
{
int i = 0;
i = i++ + ++i;
return i;
}
Questions to keep in mindValidity
Source code vs. The thing that falls out of the compiler
Additional Reading/Resources
Question of the day
Friday, September 12, 2014Quick OverviewLinux (Personal Notes - Extension)This section of notes was not discussed in lecture. This small section is a personal set of notes that I have provided in case you are interested.
Most modern kernels support dynamic loading and unloading portions of the kernel code (typically, device drivers) called modules. Linux is able to automatically load and unload modules on demand and because of this, offers great support for modules. Independent scheduling of execution (kernel thread) is an execution context and is utilized by Linux in a very limited way to execute a few kernel functions periodically. It’s important to note that a kernel thread may be associated with a user program, or it may run only some kernel functions. The key point is, context switches (the switching from one runnable task to another [2]) between kernel threads usually operate on a common address space and thus are much less expensive than context switches between ordinary processes. [3]
From Programs to ProcessesToday we take another step deeper into the abyss that is Operating Systems (CPSC 457) by taking a look at the dead piece of source code we wrote on Wednesday and it's related binary code with the aim of developing a better understanding of what role the Operating System plays in turning a pile of bytes into something that runs/a process. Before jumping into the role of the OS, let's define a few key terms. What is a Program
What is a processIt is important to note that a ‘‘process’’ can be defined a
Or
ELFELF stands for Executable and Linking Format which represents the object file format accepted in 1999 by the 86open project to serve as the standard binary file format on the x86 architecture for Unix and Unix-like systems.[4] DissectionWith no further adieu, like something out of a twisted J. R. R. Tolkien novel, let's dissect the ELF. See Ange Albertini's graphical depicition of the ELF : here. Note from the graphical representation linked above that ELF; representing a simple program for the ARM architecture in this case (mathx in our case - x86) consists of 3 major parts. Headers at the beginning and end in addition to Sections. Thus, an ELF file / an executable - is really a list of sections. The question is, what is in those sections ? The answer : Code (Program Instructions) and Data essentially. A more indepth look at the structure yields a few observations: The ELF Header (7F 45 4C 46 ...) a.k.a "The Magic Numbers" identifies it as an ELF file. The Program Header Table is composed of metadata that describes the rest of the file. The middle part - the sections, are either code or data interspersed. Continuing our journey through the structure of the ELF we arrive at some string tables that happen to hold section names; among a few other things. Finally towards the end lies a bunch of information used for merging multiple object files together. Alright, so taking a look at mathx - using a nice little tool cat we get:
You'll notice a bunch of garbled characters intermixed with a few recognizable characters litters your view (standard output). The point here is cat which stands for concatenation essentially regurgitates your file in this case -> standard output. So while it does a great job at performing it's intended purpose, your object file is composed of many different bytes, some of which have no ASCII value equivalent.
The output provided by the above command is a definitely an improvement. Note - the '-C' option we provided to the hexdump command represents 'Canonical hex+ASCII display' or so says the man pages. You'll notice four different columns. The first is the BYTE OFFSET in the file we're looking at. The second and third are the hexadecimal values at that position in the file and the fourth column is the ASCII representation of every those values contained in the second and third column; respectively. This is in fact how the file command retrieves its "answer". In lecture Professor Locasto demonstrated the delicate nature of a well structured ELF file with respect to the OS by executing the bless command and attempting to modify a single character contained in it. The meta data at the beginning of the file is important for the OS in it's mission of turning a bunch of bytes into a process; thus even "mild" modification (a capital F -> lowercase f) let to a malfunctioning / dead piece object file. BASH notifies the user with an error message - and acknowledges the fact that it can identify it for all intensive purposes as a Binary file - but for the life of it can't figure out how to turn it into a running piece of code. The question is, how does it know this ?
Certain pieces of code contained in the kernel function to process the contents of an ELF according to this format / "contract". Check out the University of Calgary's LXR for more details. Scrolling the code we can see a bunch of local variables that correspond to pieces of state and parts of an ELF. Extraction of meta data occurs here, being pulled from the headers contained in the ELF. Hence, the kernel knows how to parse and "consume" the sections that compose an ELF. The ELF does however have a bit of a dirty secret; most of it's contents are unused by the actual kernel. So we were able to gain a bit more perspective as to the contents of the ELF file by utilizing the hexdump command - but that in itself is a bit raw. Hexdump has a ton of info and is a hard to interpret. Luckily, there's readelf.
Want to know why the '| less' is there ? Try running that command without it. In my particular output (see image below) - there are 35 different sections in my ELF file. Keep in mind, as mentioned above, not all of these sections are used let alone useful. We will focus on the .text section - which is the program text / code. We can see the .text segment begins at offset 80482c0. It starts at virtual offset 2c0 and it is 21c bytes long. This information is provided for every other section.
If we wanted to dial in on a particular section of the ELF, we could use the -a option with the readelf command, like so:
OBJDUMP objdump and readelf share alot of similarities on some levels; expectation of an object file for starters. Either way, below we use objdump to disassemble an ELF file.
The -d option as you have probably gathered from above disassembles the object file. In this case, it essentially takes your ELF file, say's thanks, performs a bit of magic and returns the sections of your ELF which are expected to contain instructions - in a human readable form (ASM). What you may find a bit surprising is the sections which it returns. ie:
Our focus for today though, is on the .text section. The images below outlines the output of the .text section and it's associated x86 assembly code in both AT&T and Intel syntax. It's easier to read x86 assembly using the Intel syntax.
So what are we looking at here ? The first column is the OFFSET into the ELF file. The second column is the hexadecimal bytes - raw bytes of the machine instruction and the third column is the disassembly of this information. Summary We type:
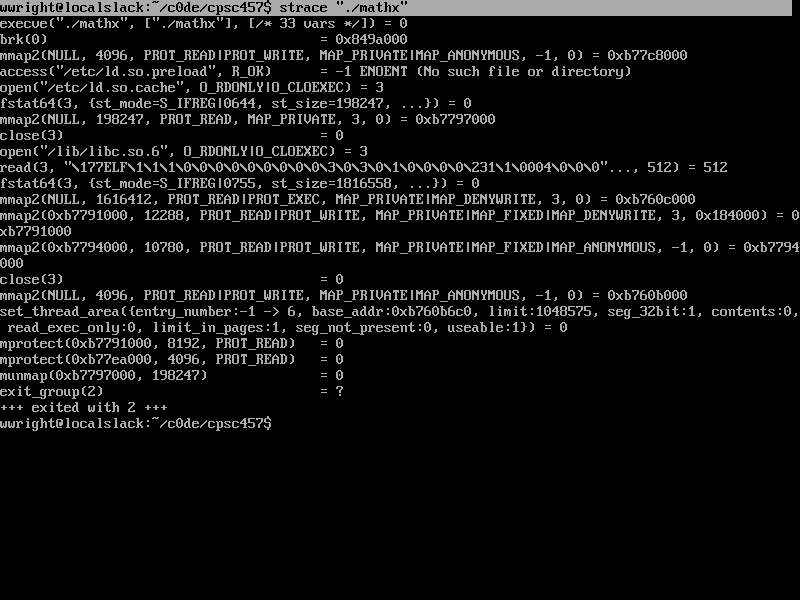
this in turn tells the Shell to invoke this program. In other words - hand this program to the OS so that it may create a new process. A few deals are signed and the ELF is loaded into memory and we produce execution (ie: jump to the entry point address - which will unwind into your main() ). Feel free to peruse the image gallery :
straceBrief summary via strace(1) - Linux manual page :
For now, we can think of system calls as functions that the kernel exploits. Hence, strace prints out a record of these things.
Brief overview of what's happening here : The currently running program (process) is the shell. It's the job of the shell to ask the OS to create a copy of itself and then start running whatever program is named at the command line. Right after the fork / creation of the clone of the shell, the first thing the program asks the operating system to do is this execve call specifying the program at this particular path. The OS in this case identifies that the file is an ELF and delegates to things such as bin_format_elf. The convention on UNIX systems has always been that the way to create new processes is to clone/fork the current process. Basically, when the system boots, there is one process running and to create any other process you basically have to fork / create a copy of yourself. The next step is usually execve on a Linux machine. On a windows machine the two are combined into one procedure called createProcess. To view the ancestory of the processes - you can utilize the pstree utility. Take note that all processes are descendent of init. In brief: The shell forks/clones itself, then asks the OS to find the program and "execute" it. Thus, the result of execve is for the OS to read the binary content of mathx and load it into memory. All of that magic happens in execve. fork is a system call. When bash calls fork its actually creating a clone of itself; fork is a system call which clones the current process. Week 2Instructor Notes
Monday, September 15, 2014Inclass Group ExerciseUsing hexdump, find the entry point and the start of the section header for our mathx program. Check out the ELF specification. Every ELF program starts with an ELF Header and typically contains a Program Header Table describing the executable. Arbitrary number of sections (we've discussed this already) and typically a Section Header Table - so on and so forth. Task of identifying the entry point address (start of execution) and the start of the section headers (offset in the file where the section header is). // C struct representation of an ELF Header
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
uint16_t e_type;
uint16_t e_machine;
uint32_t e_version;
ElfN_Addr e_entry; // Entry Point Address
ElfN_Off e_phoff; // Program Header Offset
ElfN_Off e_shoff; // Section Header Offset
uint32_t e_flags;
uint16_t e_ehsize;
uint16_t e_phentsize;
uint16_t e_phnum;
uint16_t e_shentsize;
uint16_t e_shnum;
uint16_t e_shstrndx;
} ElfN_Ehdr;
e_phoff
e_shoff
Wednesday, September 17, 2014Operating SystemsCommon Features
What is itProgram sitting between user and hardware - acts as an intermediary. Definition
Categories
History of Digital Computers- with some kind of OS, however, OS - not in terms of our definition;not an easy UI. 1940's - 1950's
1950's - 1960's Major Transition : Transistor
1960's - 1980's Integrated Circuits
1980's - Present
Key ConceptsProcessesProcess ID, Parent, Size, Memory, Resources Address SpaceAddress space needs to be allocated for a process FilesFilesystem very nice abstraction for the storage of data I/OGetting stuff in, getting stuff out. Operating System code (device drivers) are highly complex code for access - a lot of the complexity associated to an Operating System resides in device drivers. Protection and SecurityHardware Mechanisms
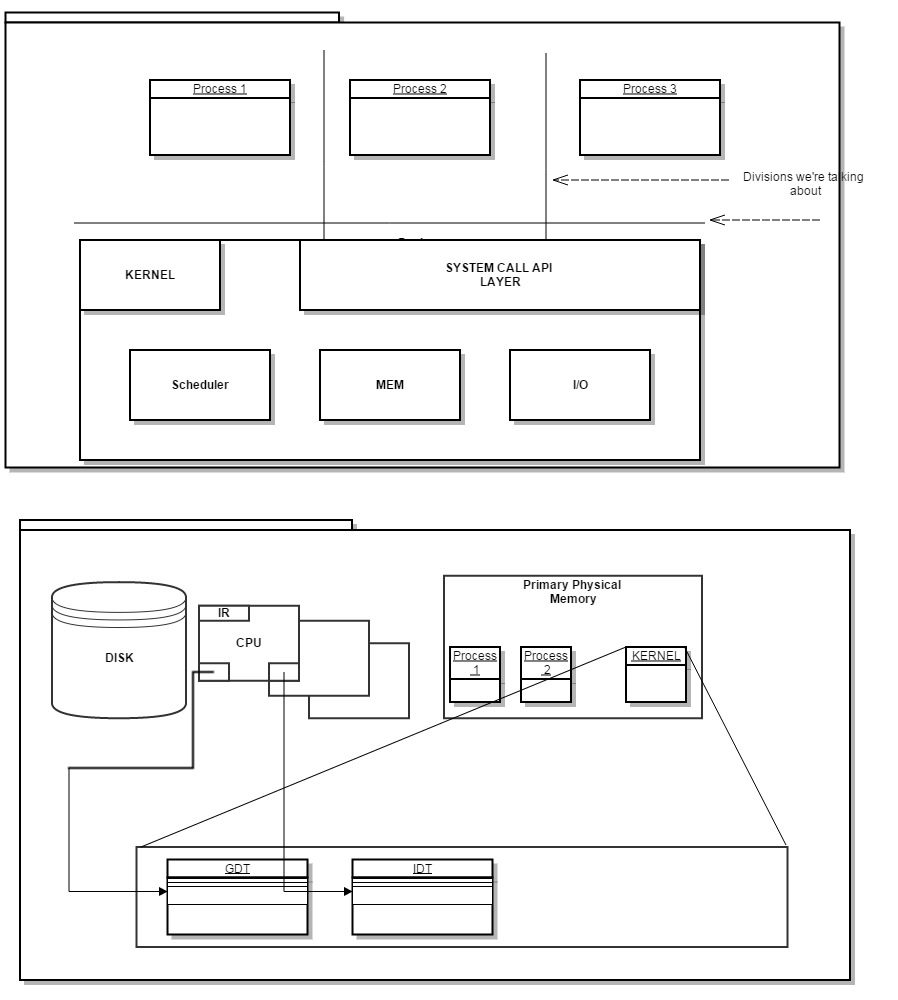
UNIX Scheduler QuoteMay be worded slightly different, the jist is: "Make a good decision - fast, rather than a perfect decision slower" Friday, September 19, 2014OS : Execute the code, it does notThe operating system DOES NOT execute the source code/programs but plays a vital role in managing such execution. It is the underlying hardware that handles actual execution. Defining: OS, Distro, Shell and KernelOperating SystemThe OS is essentially a pile of bits. It manages execution, interfaces hardware and manages resources. It serves as an API and plays the role of a privileged supervisor. KernelThe "brain". It is essentially privileged code. ShellUserland ! That place where you send people you don't like, is where the shell operates. The Operating System on the other hand is not. The shell is essentially a part of the OS, which is a user level program. DistributionA version brand. It's possible a kernel may "tweak" the kernel, adding libraries. VW is a brand of automobile. Analogy : When dealing with cars, they all have four wheels - for the most part, though VW, Honda, BMW - etc are all slight variations to some degree or another. Abstract Illustration of an OSSee : Scribe 2's Illustration or Scribe 3's Illustration. Week 3Monday, September 22, 2014Quick OverviewThe below is a list of concepts or ideas that were brought up in lecture. Some may have been mentioned in passing and may not be investigated in depth during this lecture – none the less, I’ve provided the “buzz words” or concepts that were discussed in passing.
CPU: Central Processing Unit
Your code executes on the CPU. The claim however, is that the application layer programs don’t do anything useful, unless of course they ask the Operating System for help. In other words, you can add as many values as you want to a register but unless you ask the OS for help – you can’t output the result. Questions to ask yourself
Modern CPU’s have both sets of functionality. Typically, you don’t see either – because you, as an application developer are writing in a high level language that is then interpreted by the compiler. Modes / Rings / StatesReal Address Mode
The CPU first starts in Real Address Mode (essentially – a means of providing backwards compatibility to the early versions of the x86 chip). No protection exists in this state. The things that make the division between user land and kernel / privelleged code/areas do not exist yet. This state is capable of basically doing Fetch/Decode/Execute of the core instruction set. Protected ModeThe CPU transitions into Protected mode, this is the mode that permits enforcing the seperation of user/kernel space. This is the mode that your CPU spends most of its time. Protected Mode and Ring 0
IA-32e ModeIA-32e mode is support for x86_64 (64 bit operands and instructions). Thus, if your OS is running in 64 bit mode then that’s the mode our CPU is in. Virtual-8086 ModeThis is the way to get access to the restricted 16 bit backwards compatible instruction set without having to go through Real Address Mode and give up protection. System Management ModeThis mode is almost completely separate. You can drop into SMM and the OS is entirely oblivious to what you do in this mode. The OS and the HardwareThe OS is like an event dispatcher. Constantly receiving these interrupts from the CPU, from memory, from IO devices. Constantly receiving these events/interrupts. Routing and dispatching these things; doing something useful with them. The hardware facilities of interrupts and exceptions allow this to happen. The need for hardware supportWhy do we need it, why can’t software be crafted to handle things
Fundamental Flaw with Diagram
We looked and a drew a picture on Friday, September 17 that seperated userland from supervisor / privelleged code. The major flaw in how we drew our picture is that we’ve been drawing – with a clear distinction between all our boxes, including the kernel and memory. The kernel is a big ELF. This collection of code and data (sequence of bytes) lives in memory. Same thing with each process. These processes- are nothing more than code and data. When you relate what we know from WEEK1 – with respect to ELF – there’s a .text section and a .data section, etc. Processes are nothing more than code – thus, F/D/E and some variables to do that compoutation on – and all of these things reside in memory. Kernel Code vs. User Level CodeQuestions to ask yourself:
Answer
Two bits in the CPU which is representative of the current state of the CPU to some degree combined with two bits in the Segment Descriptors is the answer to the above two questions. Supervisor Environment for x86Looking at the supervisor environment for the x86 arch – we can see that the fundamental difference between treating each set/sequence/segment of memory differently than the other is the ability to describe different ranges of memory as segments. SegmentsSegments are a fundamental construct – which refer to ranges of memory (start address, etc). The CPU needs to keep track of these segments. They need to come into being and also require management. The CPU needs to help the supervisor piece of code (Kernel) keep track of this information. The way it does that is to maintain a register. That is, the GDT register, the GDTR. Global Descriptor Table and the GDTRThe GDTR is the deep dark place that houses the address (in PHYSICAL MEMORY) of this table of Segment Descriptors otherwise known as the Global Descriptor Table. Note, the segments themselves are not in the GDT – the GDT merely holds meta data (the segment descriptors). Segment DescriptorsSegment descriptors provide the base address of segments as well as access rights, type and usage information. Each segment descriptor has an associated segment selector. A segment selector provides the software that uses it with an index into the GDT or LDT, in addition to a global/local flag and access rights information.
Length of the Segment
We thus know the starting location of the segment which may be, for the sake of example – OS data, and defined therein is the size – thus, the end of the range of memory. In that range of memory is OS kernel data – ie: variables, data structures, etc. The question is, what prevents a user level instruction from reading or writing from/into a kernel level piece of data ? DPL bits (Bits 13 and 14)
DPL (Descriptor Privellege Level); self explanatory. We can specify 4 possible priv. levels with 2 bits corresponding to the Priv. levels/rings available in the x86 arch. Thus a piece of code or data can live at 0, 1, 2, or 3. Privellege Levels/RingsRings 1 and 2 are seldom used. Ring 2 – is used for certain types of traps. Strictly speaking, the way standard operating systems use this facility. Certain approaches in Virtualization employed by the VM manager execute in Ring 0 and the guest OS is executed in Ring 1. Seperation between user and kernel level codeWhen in PROTECTED mode, the code or data that is currently executing will be marked at one of these priv. rings. This, is how we get the seperation we illustrated on our diagram. User level code – DPL bits 11, Kernel level code/data – DPL bits 00. Additional Notes from ClassLooking at the System Level Register and Data Structures picture from Instructor Slides -----> the SEGMENT SELECTOR REGISTERS hold an OFFSET into the GDT, so they select the particular SEGMENT that's talking about - hey is this user level code / data or kernel level code / data - and that's how the CPU knows which one we're talking about. It's the job of the OS (when it switches from P1 to P2 - CONTEXT Switching) to swapping in the appropriate values of the registers including the segment registers. So some privileged kernel code executes to pick the next process, and says HEY it's process 2 - as part of giving process 2 the CPU, it puts the right OFFSET into the GDT into the CS register. That's how the CPU knows what the appropriate level of code is. If you see addresses beginning with 0xc or higher, its a piece of kernel or data. 0xbfff_ffff comes before. So when we talk about PROGRAM ADDRESS SPACE, the bottom of the stack 0xbfff_ffff, and it grows downwards - so if you see addresses like bf something something something - then you know it's probably a location on the process stack. So these things, live on the same location in memory. User level stuff lives below the 0xbfff_ffff address.
The address space we detailed on the drawing showed us the distinction between user code and data and kernel code and data but..... we have more than one process on the machine..... thus our picture outlining the region of memory we defined is actually the VIRTUAL ADDRESS SPACE (a set of linear addressess) , so every process including the kernel, believes it has sole and exclusive access to this range of addresses except there is a mapping from this virtual space onto the actual physical memory of the system. This is called: PAGING - mechanism which allows us to take physical memory and split it up between many user level processes.
ANOTHER MAJOR PIECE OF SYSTEM ARCHITECTURE CIRCUITRY the OS needs to do it's job is the INTERRUPT DESCRIPTOR TABLE, another register in the CPU (IDT REGISTER) ; similar to the GDT, it points somewhere else into PHYSICAL MEMORY. So whats in the IDT ? Well it points to INTERRUPT DESCRIPTORS -- which are pieces of meta deta describing INTERRUPT VECTORS / INTERRUPT SERVICE ROUTINES. Like said before the OS is really just a big event dispatcher. One of the first/earliest things the kernel does, is to setup the IDT, because without an IDT table - it can't do it's work (handling events). The IDT is nothing but a TABLE of FUNCTION POINTERS >into< the KERNEL CODE. Wednesday, September 24, 2014Instructor Notes
public class A {
int foo()
{ return 1; }
}
public class B {
void bar()
{ A a = new A(); a.foo() }
}
Compiler Enforced IllusionIf we talk about things like package visibility - then what we have above is default package visibility, etc. However, looking at the actual compiled code - the only thing (Java being a special case) governing these separations that we've learned about is the compiler. Any instruction in the .TEXT section can transfer control to any other instruction in the .TEXT section. Many of these so-called restrictions are gone when it hits the CPU. If user-level code cannot access kernel functionality or kernel data structures, how do you accomplish something like a print to the screen? System CallsThe system call layer can be viewed in two perspectives: What system calls are available to me as an application developer ? Kernel source code related to system calls: The system calls available depend on the architecture even though generic API is related to the underlying capabilities of the CPU itself. University of Calgary LXR - syscall_table_32.S What is syscall(4) How to invoke a syscall (Details found in slides) System call number goes into the EAX register (ie: 4 for Write)
1 went into EBX - The first argument to Write in our inclass example was 1 - which is a file descriptor, where in 1 refers to Standard Out. ECX is only four bytes long and in our example we pass it a pointer (address) to 'msg' which was a string, and then how many bytes we want to print out into EDX. Following that was an instruction: int 0x80 - the int instruction in x86 is the way to invoke a software interrupt which is where the IDT comes into play. The CPU holds a register that points to the location of the IDT. IDT
Friday, September 26, 2014Instructor Noteshttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes/SystemCalls Overview
write.asm‘’’Taken from Instructor notes for today.’’’ Example of the function call conventions on x86 setting up an activation record between main() and foobar(): 08048414 <foobar>: 8048414: 55 push ebp 8048415: 89 e5 mov ebp,esp 8048417: 8b 45 0c mov eax,DWORD PTR [ebp+0xc] 804841a: 8b 55 08 mov edx,DWORD PTR [ebp+0x8] 804841d: 8d 04 02 lea eax,[edx+eax*1] 8048420: 5d pop ebp 8048421: c3 ret 08048422 <main>: 8048422: 55 push ebp 8048423: 89 e5 mov ebp,esp 8048425: 83 e4 f0 and esp,0xfffffff0 8048428: 83 ec 20 sub esp,0x20 804842b: c7 44 24 1c 2a 00 00 mov DWORD PTR [esp+0x1c],0x2a 8048432: 00 8048433: c7 44 24 04 08 00 00 mov DWORD PTR [esp+0x4],0x8 804843a: 00 804843b: c7 04 24 07 00 00 00 mov DWORD PTR [esp],0x7 8048442: e8 cd ff ff ff call 8048414 <foobar> 8048447: 89 44 24 1c mov DWORD PTR [esp+0x1c],eax Calling the write(2) system call via the INT 0x80 mechanism: (eye@mordor syscalls)$ objdump -d -M intel mywrite mywrite: file format elf32-i386 Disassembly of section .text: 08048080 <_start>: 8048080: b8 04 00 00 00 mov eax,0x4 8048085: bb 01 00 00 00 mov ebx,0x1 804808a: b9 a0 90 04 08 mov ecx,0x80490a0 804808f: ba 0b 00 00 00 mov edx,0xb 8048094: cd 80 int 0x80 8048096: 89 c3 mov ebx,eax 8048098: b8 01 00 00 00 mov eax,0x1 804809d: cd 80 int 0x80 (eye@mordor syscalls)$
$ nasm –f elf write.asm $ ld –o mywrite write.o The IDT plays a central role in dispatching software exceptions/interrupts. Simulating a CPUSimulating a CPU executing our code, what happens first? Program starts up, EIP is now pointing to _start, the instruction gets executed (F/D/E, F/D/E, PC incrementing along the way) – we’re in userspace, and we’re following the system call calling convention – but notice what is not happening. We are not writing a kernel address into EAX. If you recall, we found out where syswrite (which was c0, etc); yet we are not writing c0 into this. Why not ? Take HomeUnderstand the dance between user space, the CPU and the OS. Important to note ! How does this differ from a function call ? (privellege translation).
Activation RecordContract between 2 functions (‘’’caller’’’’ and ‘’’callee’’’). The ‘’’caller’’’ sets up the first half of the AR whilst the ‘’’callee’’’ sets up the second half of the AR. Week 4Monday, September 29, 2014Instructor Noteshttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes/Creation Overview
ShellshockThe problem is that BASH should simply parse the end of the function definition. Key SentenceOne way to look at a process – is to think of it as a virtual cpu. What is a process ? Executing piece of code, what this means is the CPU is executing it’s F/D/E algorithm on your instruction stream. Because the CPU can’t execute all processes at once, the OS needs some means of keeping of a particular process / program undergoing execution. Thus, a process is virtual CPU, in other words a set of CPU registers that the OS keeps track of. Thread Notionjava.land.thread Certainly an executing program has more than just a register set. Persistent data. Process id. Events expected to handle in the future/now, etc. Thus there is all this ‘’’state’’’ associated to a process. And – a process needs memory to operate on. So, you can round it all out to a CPU context with associated meta data and a process address space, which, maps very well, to the things that an OS keeps track of on behalf of all processes. Process Control Block‘’’task_struct’’’
One of the main components of a process – the repository of meta data in the OS kernel that the OS maintains on behalf of every executing process. There is a significant amount of meta data associated to a process. Parts of this PCB are there because they are related to OS concepts. Is the process runnable (state of the process)? What’s the PID ? Memory space ? There is also a bunch of details related to the details – related to keeping a process scheduled, making sure you’re protecting access to it, pending signal files, etc. volatile long stateFirst field in the task_struct, semantics are : current state of the process . Basically tells us, can this process use the CPU . In some sense a process doesn’t care what state it is in. To some degree in believes in the fiction that it is executing all the time. mm_structDefines the Process Address Space. This is how the kernel helps keep track of the PAS for this process (with an instance of mm_struct). personalityWhat kind of program is executing. We’ve seen an ELF can turn into a process, and shell scripts can as well (another type of personality). JVM would be another type of personality. pid_t pidreal_parentWho forked us. children / siblingWho did we fork. credentialsRelated to the user ids who own the process, etc. ptracedAre we ptraced or not. Drawing a process state diagramBirth – fork() system callThe first event in a processes life. Thus, a first event is a fork() system call – via a privlleged call. This creates a new copy of the process. The OS has created another PCB for it – now given a neglect for exec, the process is in a state to be run. TASK_RUNNABLE. This doesn’t imply it’s actually on the CPU but that it is eligible to be run by the CPU. OnwardWhere do we go from there ? Several things could happen. ‘’’1’’’ major one could be that it is given the CPU – process is running, its context has been loaded into the hardware. Its values are in the registers, F/D/E are taking care of its instructions. What is another possibility ? How about acquiring input – this implies we are waiting for something to happen – and sitting around waiting for something to happen is not a very efficient use of the CPU, thus – the OS says “time for bed… sleep”. Waiting on I/O – see TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE. Fork in actionWe were shown a program in class wherein we used fork to create a process. Wednesday, October 01, 2014Process CreationSemantics of the fork system call : To clone/duplicate the current process. The task of creating a new process is split into three steps: /bin/bash -> fork(2) (1) --> /bin/bash, PID: 1235 ---> execve(2) ----> exit(2) (2) (parent) could be in a state of waiting --> wait(2) ---> This arrangement raises a few questions. Man pages: duplicate the current process - Is the /bin/bash (PID: 1234) -> fork(2) a waste ? Since the pattern is fork -> exec , it doesn't make sense to duplicate the entire address space. There is a neat mechanism called Copy on Write. The idea is to duplicate the structs in the process control block (memory mapping that describes where the addresses are) . We duplicate the process control block includin the contents of the MM struct - we will not actually duplicate the pages and the page contents themselves (pages of mem) only when the child begins to write * Only copy when we need to do things * System calls can be provided by the parent shell (process) so there is no need to fork them.
Looking at spawn.cGoal of this: Forking off a child and having that child do an execve. unistd.h - good file to include for system calls. "After the call to fork returns we have two processes processing the statements"? The child (return status of the fork system call will be 0) The child executes a very simple program. $file bin/arch $arch - tells you what the system architecture is, "hey you're executing on an intel i-32 bit machine" Any statements written below the execve call will not be run. How to convince yourself ? "If only there were a tool". strace.... $ ls $ cat trace.sh you can cut down the amount of info strace tells you about, ie: -e -> can specify that you only want system calls related to -i * print the instructor pointer -f * follow (if not done - will just follow the parent)
strace -i -f -e "traceprocess" -o spawn.out ./spawnx chmod +x trace.sh $ ./trace.sh output of arch: i686 .... some stuff you can see ..... $ cat spawn.out second column is the instructor pointer - parent says go ahead and execve myself -- immediately before this, bash said "you want to exec the spawn program", so it did, blew away the address space and replaced it with spawnx. fork() is actually implemented with clone() - allows us to create independent light weight processes.
Process Address Mechanism (chit chat)Any copy on write happening ? - definitely execve replaces the contents this clone of spawnx - now we have two copies of spawnx, the question is - is the address space for the two processes the exact same ? fork() is writing a value to a memory address, and this is happening at the same time. -> after we execute : pid = fork(); address space of P : .text .data (heap) main() -> pid: (stack) address space of C : P-> mov pid, eax; C-> MOV pid, eax; address space of P : .text .data (heap) main() -> pid: (stack) address space of C : .text .data main() -> pid: 0 (heap) (stack) A process is a virtual program counter. At fork() it is a seperate process (own PID) everything. At execve - contents of address space is blown away and replaced with bin/arch Copy on WriteCopy on Write - only copies the pages that modified. "copies that thing and allows that instruction to write". - How do you notice a write? (touches a little bit on the structure for the address space - which is to be talked about seperately). Hardware traps. Deals with pages of memory (illustrated in class). How do the two processes communicate ? ie: parent talking to child. Copy on Write seems to screw this up. IPC mechanisms (shared memory -> bunch of system calls) or.... the very notion of threads is how we can share parts of our address space (the entire idea of a LWP - something achieved thru a clone system call). Knowing the difference in semantics between a fork() and clone() - IMPORTANT - QUIZ Copy on Write() is a differal of work - wouldn't hurt to understand it. sys_clone (looking at the LXR) - really quite short and wtf, it calls do_fork. Multiple levels of abstraction going on here, there's a fork system call - but not really, there's a library routine and that's the one that is used. You call fork -> compiler links against the library version of fork(3)->clone(2) now we are in the implementation of the clone system call ---> do_fork() * internal routine to the kernel however the meat of the work is in copy_process (which duplicates the PCB and copies the data) but if we're forking not all the memory address contents (whole idea of Copy on Write).
Friday, October 03, 2014Process Address SpaceRounding out discussion on what a process is. Can be represented as a virtual CPU to some degree. One of the final defining pieces of what a process is: - non-persistent storage of a process (volatile memory) characteristics The process address space is one of the vital elements of being a process. A vital place to store that stuff. The PAS is an abstract concept, different than phys memory that's there. Allocating/Deallocating it is a major task of the OS. If every process on the machine believes it's the only process on the machine, then how does it make use of -
Internal structure of the PASThe order inwhich these elemnts appear in the PAS <picture look at instructor slides - low addr -> high addr) If an ELF file is sort of this dead image of a program before it turns into a process it eventualy winds up in PAS. 2^32 -
KEY COMPONENTS of PAS.text seg (code) = ro .data seg (initialized data) .bss seg (unintialized data) The ELF --- contents --- transferred into physical memory - which wind up in these places of the PAS.
Programs actually invoke functions to get their work done thus need a place to keep track of (variables, etc) --> PAS Creating a table of STUDENTS, without prediction of the number of students.... The heap growing and shrinking to the dynamic needs of a program. Memory Address TranslationMemory address translation (hilighting) the PAS constraints (its a virtual addr. space) 0 - 2^32 There is a mapping between the physical address space and the virtual address space. Because we can't promise every process has four gigs of memory. Doubtful, that's probably a lot of memory. Where would you fit stuff........................................... Giving compilers and programmers the freedom to have acesss to all the addresses, but what if you were poor ! Like Michael Heiber, so whats going on is a translation from the virtual address space to the physical memory. Figure 3.1 - Segmentation and Paging. Slide 4 - Why have a PAS abstraction ? purpose : If I give the programmer the ability to write to any physical memory location - since programmers suck, direct physical access is a bad thing. And we've seen processors when in PROTECTED mode don't like giving you the power. Thus potection is sort of number one. Answer number two, supposing you are given the trust, here have physical address number one. I could write my value into anywhere, great. If you were to give the power to the next person - then you get issues with people overwriting each others stuff. Hard to control. Thus, we implement a virtual space and implement a mechanism for mapping.
Other definitions of PASDepends on physical memory being organized into PAGE FRAMES. A pas is a collection of these things called pages. Convenient when writing system level code to refere to things in fixed sized chunks. A page is typically 4k or 8k worh of bytes. Textbook: PAS is an abstraction of memory. Common OS - caches FILE IO in memory, thus, when you check your system for available memory and you see 7 gigs, you typically don't. <picture of a real process address space - cat /proc/self/maps> memory regions - sub section/piece/range of this process address space! cat file asked to dump the file that describes it's own address space. -> a direct reflection of mm_struct $ cd /proc known as a virtual file system - pseudo file system kernel meta data bound to a particular location in the file system name space - convenient way of reading out kernel state. welcome ..... all the numbers you see in a directory listing are the processes. etc. the self macro resolves to the current process. Ie: cat /proc/self/maps for the processes you don't own - then you won't be able to read the PAS of something you don't own or have access to. $ cat /proc/self/maps orientation: first set of cols is the state and end address of a particular memory region - 32 bit addresses. denoted in hex second set of cols - permissions on that memory region, deduce rw-p (p is private) third column - prob. an offset 4th col - descries the device where that file came from 5th col - is prob. a size of whats there 6th col - what do you think lib/libc-2.12 is ? C ibrary, each library seems to be mapped four times into the PAS - further down the list in the 6th column, /bin/cat --- r-xp = code (text seg) - further below that /bin/cat with write ---- = data seg - notice the [heap], pulling new objects out of the heap (grows and shrinks - has to grow downwards, cant grow into global data and text) - couple anonymous memory regions.
vdso - is not in the elf, the os creates it on the fly as it loads the program, its purpose is to hod a little shim of code to specify how a process is made. (not sure about this one) notice that vdso also moves around in the PAS - for security so avoid being easily targettable.- it changes with every process. anonymous memory regions - are actually quite useful, which you can create using mmap - you can add to the address space and unmap to. if you just need dynamic data and you don't want to use the heap is one possible use. programs that implement custom memory allocators may use this also. notice the ranges in the first left two columns are bigger than 4k. r--p = const data/variables , yada yada yada ld: Linker (Dynamic Linker)What is ld ? ld is the linker (the dynamic linker) - ie: how to bring in another library into my PAS ? ld. recap: PAS- virtual address of spaces kernel keeps track of these memory regions these memory regions are important artifacts for keeping track of shit. fork and clone create address spaces. <SLIDE ON PAS OPERATIONS> execve will wipe out the entire contents of a PAS mmap - will either grow an existing memory region or create a new one for you. If given a task to write a c program that creates a new memory region and writes a seq. of x87 machine insutrctions into it, and jumps to this new place...to start executing the code..... (smirk - implies this might come up)
<slide page - 13 - picture- > <slide page - 15 - picture -> mm struct describes the PAS.
mm_structEvery process has an individual MM STRUCT. Q: when the new process address space gets created ? are things like the heap always the same size ? ---- when a process is created, is something like the heap a default size ? SUSPECTED : yes..... Q: when memory is allocated to a process, is there a mechanism that says hey - this is what you can / have been mapped to ? mmap - is used for adjusting the memory region, but what is the MEMORY ALLOCATION strategy the OS takes ? image having a range of memory that you need to parcel out to process/tasks, looking at the slide 17 - if that's filled up, and someone sends I need 4 megs of mem ...... what do you do ? The OS needs to somehow determine do I have a region of memory that is atleast 4 megs large ? Then if it can find one, which one does it give back to you --- MEMORY ALLOCATION questions..... we'll discuss later ! Week 5Monday, October 6, 2014Instructor Noteshttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2013/Lecture_Notes/MemAddr OverviewIn no particular order - Ideas, topics, concepts, buzz words, things..... discussed.
Virtual Address to Physical AddressVirtual address to physical address guarantees these two processes are modifying different memory even though they have the same virtual address. There's a piece of the CPU called the MMU, it is the job of the MMU to translate to logical addresses to physical addresses. But alas, the MMU cannot do this alone, the MMU needs the help of datastructures kept by the OS. The OS stores some state, called Page Tables. <FIGURE 3.1 IMAGE - Segmentation nd Paging> Job of the MMU is to translate into a point in the linear space, and the paging part of the MMU translates it to a physical address ( a place in RAM ). Logical Address ----> Linear Address / Virtual Address ---> Physical Address 4 terms describing 3 things. $ nm one | grep michael The first step in the memory address translation is known as SEGMENTATION . Part of the MMU. So what does a logical address look like ? Two components. A segment selector and an offset, often in ASM it may look like: ds: 8049858 804* being the offset, and ds being the name of an x86 segment registration. These segment registers hold a value, ie : ds may hold a value, and what's in the ds register - is a segment selector, other words something that helps select a particular memory segment. A ds selector is nothing more than an OFFSET into the GDT. Ie: Entry 73 into this table is the segment we're talking about. GDT : What's in it ? Segment descriptors. Segment Descriptor - three main pieces of info : DPL, Base Address, Length Second part of logical address becomes an OFFSET into that segment. IT DOESN'T MATTER ! Most OS's don't use the first half. Translating a logical address -> 1st step: ignore segment selector --> look at offset into linear address space. Thus 8049858 becomes our linear address / virtual address. A number of segment registers, any one of which can hold a segment selector. MMU is a beast... So we have some linear address (8049858) the hardware needs to translate this to a physical address. We want this to exist in different address spaces. The OS rescues the MMU, and says I can hold some tables for you. So you can lookup - ON A PER PROCESS BASIS - the address which will map to a physical address. 8049858 is deep somewhere in the space of Lin.Addr (diagram), but note 8049858 is NOT an address, you think its one, but your OS knows its not. It's a set of lookup bits. String of 32 bits, chop that up, the parts become indexes into the page tables. Linux kernel actually uses four but our diagram shows three. Dir bits somehow select an entry in the page directory. In the task struct (mm) , a field called pgd -> Page Global Directory. The pgd value on a per process basis points to the base of the page directory for that process. The OS keeps track of the pgd. Another ex. of how the OS is keeping track of all the meta-data for all the processes. The value of the PGD is actually a physical location. Simulating the process: Remember 32 bit virtual address... How many BITS should the OFFSET be ? Enough to address every byte in a standard page size of 4KB. - 12 bits How many BITS should the DIR be ? - 10 bits How many BITS should the PAGE Table be ? 4 gig address space / 4 KB page size - 10 bits
Bit representation: 0000_1000 0000_0100 1001_1000 0101_1000 Now to seperate: 0000_1000 00 / 00_0100 1001 / 1000 0101_1000 d32 / d73 / d(2048 + 64 + 16 + 8) DIR / PAGE TABLE / OFFSET Dir ---> Page Table (Yields PTE) ---> PTE points to a physical memory address (start of the page we are talking about) The MMU does this on the fly. CPU - working with memory (quote on quote being slow) deals partially with all these lookups happening in parallel. Thus to look up one memory address requires two look ups into kernel data structures. An optimization introduced into many memory management units is the TLB - which holds a successful cache of memory lookups. Everything you've seen is a virtual address. For the most part it doesn't. If you were doing embedded dev. on some mobile platform (ie) you'd be dealing with physical addresses. Given the state of the GDT, state of some segment registers, with a standard 10/10/12 scheme - are you able to do this on an exam ? RECAP: This mechanism - two parts - purpose translate logical addrs to physical addrs. "This is the thing every process thinks it has", needs help from the OS to keep the state and the MMU. Supports the illusion of personal address space. Where is the user-land / kernel split ? That's in the segmentation - remember Linux has a flat segmentation model. Wednesday, October 8, 2014Friday, October 10, 2014Week 6Monday, October 13, 2014NO CLASS - ThanksgivingWednesday, October 15, 2014NO CLASS - MIDTERM EXAMFriday, October 17, 2014Overview
Resource ManagementResource management in systems (systems include programs (mobile app, etc)) require worrying about managing tangible resources (data structures, etc). Memory Management: Page ReplacementWhen we go through this mechanism of virtual memory and paging - and we need to swap in page from disk AND physical memory (no free frame) is full - who do you pick to kick out ? This is the key question. Random Approach: One ExtremeSimplest approach would be no meta data - generate a random number and nominate the number generated as the one who gets the boot. Random - simple to understand, bad idea; don't do it. If random is bad, is there a perfect approach ? Surprisingly yes. Optimal Approach: Another ExtremeThere is an absolutely perfect algorithm for selecting the page frame for kicking it out of memory. /dev/crystalball has the answer - select the frame that will be selected furthest into the future and you will minimize the number of page faults. Unfortunately - such a crystal ball does not exist. The utility of knowing there's an optimal approach and given a set of memory references and particular number of physical page frames - you can simulate the optimal approach and you can determine the number of page faults. You can do this by hand for a specific case but the problem is you don't know the complete set of memory references all the way into the future. Now, if we shouldn't pick one at random - what if we kept track of when the pages were first referenced. So, we can kick them out in FIFO order; first one in maybe the one you haven't referenced in a long time. Imagine a program starts it reads its first code page, that gets swapped into memory -> it goes and does a bunch of other stuff (executing other code, referencing a bunch of other data) - so is that first page likely to be referenced ? It depends on what the program is actually doing, but maybe not. Thus, if we keep a big linked list of pages in the order in which they're brought into memory (FIFO implies we just get rid of the one at the front of the list). This however suffers from some of the same disadvantages the Random option incurs - because you may be selecting an important frame; FIFO order may or may not have a correspondence to how heavily used a particular page is. Linked lists are a bit of a pain also, maintaining all the pointers as things age, etc. We're then after a way of improving FIFOs knowledge of what happens to be in a particular page....How do we make FIFO more intelligent. Second Chance: Finding the middle groundThe key piece of information we're interested in, is a form of tracking when a page was last accessed. We will still maintain pages in a FIFO order - but with the addition of a small amount of meta data that allows us to keep track of whether or not the page has been recently accessed (read/written); access bit. So before booting someone off the list - we check - has this page been accessed (is the access bit set to 1) ? if so - we will give the page a second chance by moving it to the back of the list and proceed to check the next page (in this case, 2nd page), continuing on until we find an access bit with 0. Another key point to consider here is that when moving a page to the back of the list, we reset the access bit to 0. We have yet to fix the linked list nature of FIFO - ideally what you want is a circular buffer, so that you can just move a pointer around to determine the front of the list versus moving a node around in memory. Note: The access bit is approximating "in use". In fact, all of these things we've covered so far in this lecture - are an approximation of what the software is doing. The assumption to this point is that we can obtain and maintain meta data for free - but who is doing us the favour of maintaining this data ? Hardware. Yet another example of cooperation between the OS and the hardware. The memory management unit (MMU) sets this "access bit". A brief overview -> when the MMU is asked to resolve an address involved an instruction - when that resolves to a page - it marks that page as accessed. It is up to the OS to check that state and reset it, as per our example, resetting it when it goes back to the end of the FIFO list. The hardware doesn't have the intelligence to manage an arbitrary length linked list and the OS is far too slow to set the bit - thus, hardware sets it very quick and only when we need to manage the algorithms meta data do we unset the bit. Second Chance: IssuesProblems remaining with Second Chance
Least Recently Used: Dialing inKeeping track of the history of each page
If we can identify pages that haven't been used in a long time - then we can assume it won't be used in the near term future (probability). A conceptually simple LRU scheme is going to maintain a list of page frames in LRU ORDER so that page frames at the front of the list imply those page frames which have been Least Recently Used. LRU: Complications
The fact is you would need an unbounded counter or hardware that can manage dynamically sized pieces of memory (which it can't). Thus, any "realistic" implementation of LRU has to rely on some limited hardware facilities. A basic implementation of LRU would maintain a counter for every page frame and every time that page frame is referenced, we shift in a bit to the counter. After some periodic time has elapsed (CPU clock) we can scan all the page frames and age their respective counters. Now when a free page frame is required, we could scan all the page frames and pick the oldest one. Now this approach works, but why is it inefficient ? Scanning every page frame that the OS is keeping track of at every clock tick is a waste ! So, we quickly realize that we can't have an unbounded number of bits to keep track of this counter "aging" and iterating the entire list is not efficient. In x86, the PTE has a few bits lying around, so perhaps stealing two of them wouldn't be the worst thing in the world to use as a counter for a classification of categories related to the age of the page frame.
NFUNOT Frequently Used is basically LRU that keeps a counter on a per page basis, which doesn't work and the reason being, because under certain work loads a heavily used page (in the past) would still maintain a relatively high "frequently used" counter, thus you would not evict it when you should. One way to simulate full LRU is to take NFU (which keeps track of the page usage) and then implement/use "aging". The problem here again is, how many bits do you have available to track such meta data ? Inclass ExamplesNon-optimal Example Optimal Example Week 7Monday, October 20, 2014User level memory management Brk(2) helps manage heap. Servicing requests (gimme x units of mem) External frag Pg size chunks – 4k – int. frag Brk(2) always returns a linear contig. Piece of mem Wednesday, October 22, 2014OverviewClass Starter Exercise
First-fitSeeks to satisfy an allocation by scanning from zero (always starting at zero) until it finds the first hole that fits the criteria. Next-fitEssentially first-fit BUT it remembers where it's been. Thus, if it scanned and found a hole at 45 and allocated 2 units of memory, it would remain at 47 and begin scanning from there. Best-fitScans all free chunks to find the one that is the closest size to what is required. Thus if you need 4 units of memory and there's a 5 hanging out, it'll pick that one. If there's a tie break, flip a coin - perhaps it will pick the lowest number in terms of memory address. Worst-fitGreedy. Looks for the biggest region - and the logic being: if its a big region, you can prob. push a lot of memory requests into that area before you run out of space. Comparison Summary
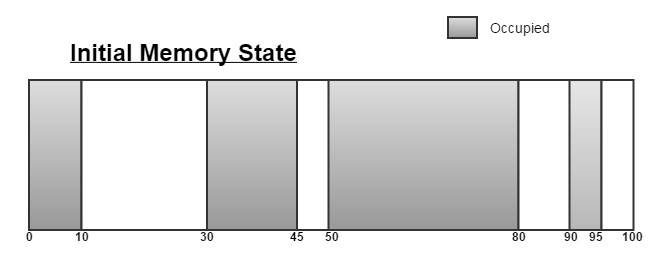
Internal vs. External FragmentationFirst thing to realize is that they emerge from two different problems. When you have fixed size physical memory and you attempt to run many processes within that fixed size physical memory and these processes are all of arbitrary size and they have arbitrary future demands on memory, external and internal fragmentation can occur. But why ? ....
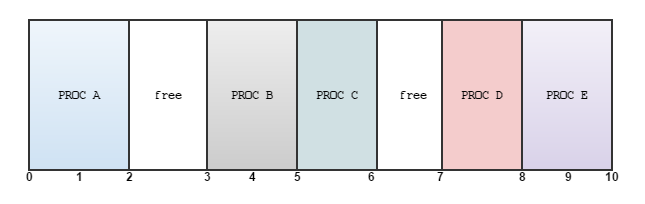
External FragmentationLooking at the diagram above, we have a fixed sized memory (0 - 10 units), where process A fits nicely in the first two units, process B loving life in the two units it has, so on and so forth.... but then comes along Process F comes along and requires 2 units of memory. Unfortunately, no luck. Yes, there are two units of memory free however they are not coalsced (not continuous) - an example of external fragmentation; wasted memory external to programs. Solving External FragmentationAllocate memory in fixed sized predictable chunks (pages). Therefore we alleviate the wasted slices/slivers of memory between processes. Note - this happens in the context of paging and memory address translation that we've discussed in class to date; we can utilize the physical frames [2, 3) and [6, 7) despite their physical discontinuity due in part to the mapping of virtual addresses (linear address range) to physical addresses which enable us to have a continuous virtual address its physical state. See page tables and address translation notes if you need to refresh. Internal FragmentationWe saw how wasting physical memory lead to external fragmentation, and we were able to solve that by allocating pages of fixed size in combination with paging, but what about wasting space inside these pages. Consider for example asking the OS for a page via the brk system call. Now assuming you only store 64 Bytes of in a 4KB page - then of course we are not using the full extent of memory inside a page. Thus, internal fragmentation relates to the wasted space inside the page. Solving Internal FragmentationRequest for dynamically allocated memoryKnowing how to program, particularly in C and requesting dynamic allocation of memory can be carried out by some of the following, what follows is a very brief overview of each. malloc
calloc
realloc
free
below both mmap and brk allow you to ask for more memory (fixed page size chunks) from the OS directly. There are many good use cases for the following two system calls despite the common case where most people are advised to go through the glibc means. mmap
brk
glibc exploration by examplellist.cWritten by Professor Locasto, original link to source: http://pages.cpsc.ucalgary.ca/~locasto/teaching/2013/CPSC457-Fall/code/llist.c.txt outputhttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2013/Lecture_Notes/UserMem questions
struct node
{
char data;
long num;
struct node* link;
};
struct node *tmp = NULL;
tmp = malloc(sizeof(struct node));
Value of the expression sizeof(struct node)
char data - character is a byte - however, the compiler is aligning these memory accesses. Thus asking for a char in a struct, you get 3 bytes for free. gdb analysis of llistIdentifying the extra bytes glibc allocates. 0x8049ff8: 0x00000000 0x00000000 0x00000000 0x00000011 0x804a008: 0x0000004d 0x00000000 0x0804a018 0x00000011 0x804a018: 0x0000004d 0x00000001 0x0804a028 0x00000011 0x804a028: 0x0000004d 0x00000002 0x00000000 0x00020fd1 0x804a038: 0x00000000 0x00000000 0x00000000 0x00000000 0x804a048: 0x00000000 0x00000000 0x00000000 0x00000000 0x804a058: 0x00000000 0x00000000 0x00000000 0x00000000 0x804a068: 0x00000000 0x00000000 0x00000000 0x00000000 Friday, October 24, 2014OverviewKernel Memory ManagementWeek 8Monday, October 27, 2014Wednesday, October 29, 2014Friday, October 31, 2014Overview
Rough NotesFocus today: Ensuring that the work being performed by the scheduler is efficient PreemptionAs we discussed last lecture, preemption is vital to concurrency and or the illusion of such. Preemption is essentially the act of interrupting a "task" currently being executed by the processor. What enables itAn oscillating crystal in the CPU enables preemption. Every so often, generate an interrupt. Another prime example of the close relationship between an Operating System and the Hardware. Recally, that an OS could be sleeping; a user level program is currently on the OS. Thus, this mechanism enables us to wake up the OS, signalling that we need some work performed on its behalf. Policy Versus MechanismRelated to how the scheduler performs, data structure and core algorithm configured by core policy. Ver. 2.4 Scheduler sched.c (see the Instructors wiki entry for a link) entry point- asmlinkage void scheduleThis is the entry point - called from kernel code. Calls can be made either explicitly or implicitly. corefigurative "core", looking at sched.c we can see:
repeat_schedule:
/*
* Default process to select..
*/
next = idle_task(this_cpu);
c = -1000;
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p, this_cpu)) {
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
Essentially a for loop. list_for_each runs over the entire run queue not that task list - basically like finding the maximum # in a list. goodnessThe goodness function tells us the dynamic priority of the process. /* * This is the function that decides how desirable a process is.. * You can weigh different processes against each other depending * on what CPU they've run on lately etc to try to handle cache * and TLB miss penalties. * * Return values: * -1000: never select this * 0: out of time, recalculate counters (but it might still be * selected) * +ve: "goodness" value (the larger, the better) * +1000: realtime process, select this. */ In linux the notion of real time processes is faked via: weight (see sched.c for additional details). TODO: policyTODO: multi processorsTODO: virt. mem of task/process (mm_struct)process affinityRelationship established between processor and process because of cache, etc. Big O NotationO(N) - runs over the entire run queue. TODO: Ver. 2.6 Scheduler =TODO: Remainder =Week 9Instructor Noteshttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes#Week_9 Monday, November 3, 2014Quick Overview
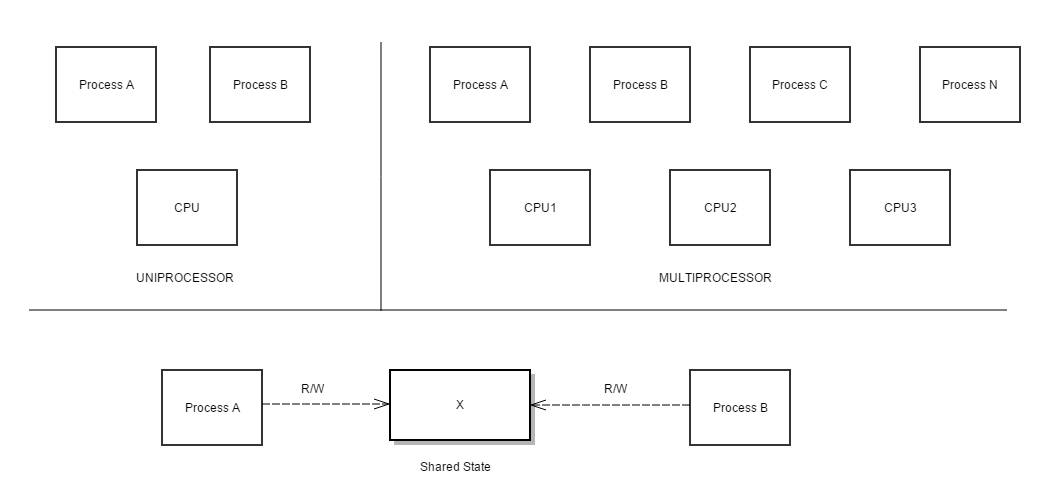
Emerging problems from successful multiprocessing
Sharing a piece of memory (variable, etc) is essentially communication (IPC). Question is, how do we coordinate two tasks to share state/resources safely ? Race condition
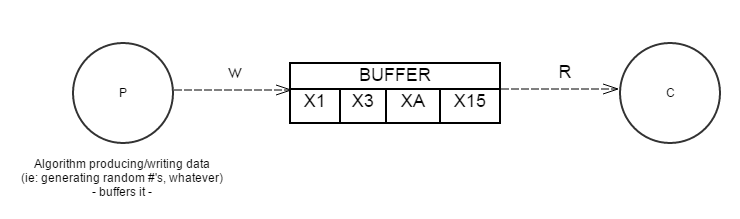
Mutual ExclusionThe idea: Don't let more than one thread into a critical section at any one point in time. Critical SectionThe potential for shared state (ie: two different processes - where in , each has to access certain stuff from the same "shared" location) Classic Problem Examples/ScenariosProducer - Consumer
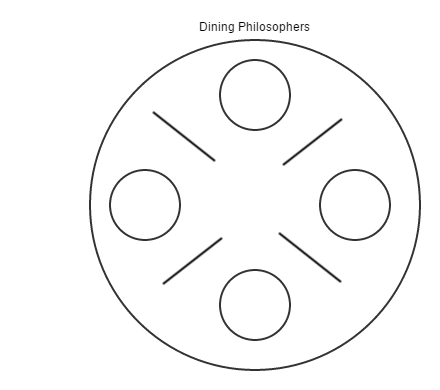
Dining PhilosophersProcesses have to coordinate over who gets access to limited resources. The picture below illustrates a classic example one philosopher must possess two chopsticks (limited resource) in order to eat.
Readers + WritersDon't want readers waiting as they are not modifying state just observing it. Thus, we require a means of determining what kind of process "you" are. Potential SolutionsDisabling InterruptsWorks with respect to one process, though not globally on multiprocessor systems and raises the question - how long is the critical section? (ie: interrupts disabled - providing the "loose" illusion of concurrency). Lock VariablesWho has access to the lock ? etc. Heart of the SolutionWe require an atomic instruction (something the CPU understands natively) that tests a piece of state (ie: lock variable) and sets it in the same cycle. CMPXCHG (Intel manual) is one such example. SemaphoreAble to keep a list of how many people want it. MutexOne at a time please. (Check out code from MOS - page 131) SpinlocksEssentially a while loop - interrupt when done. Programmer ResponsibilityAdvisory locking - it's up the programmer to get it right; follow order. ie: Everytime you touch 'x', you must lock M. Granularity LockingHow deep do you go ? This is a design question - where in the finer grain you can implement without affecting performance is probably the right answer. Wednesday, November 5, 2014Instructor Slideshttp://pages.cpsc.ucalgary.ca/~locasto/teaching/2014/CPSC457/talks/deadlock2014.pdf Overview
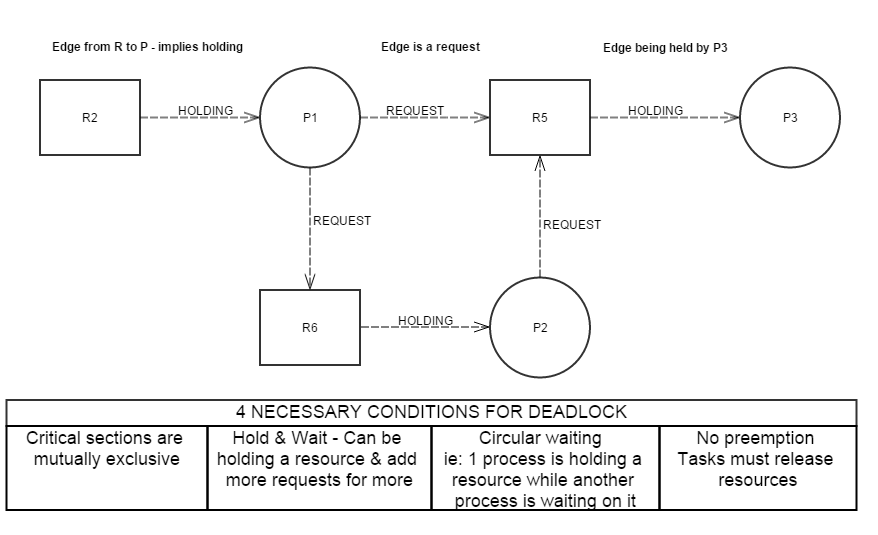
Deadlocks
Avoiding DeadlocksBreak any one of the four conditions listed above in the table - poof ! deadlock avoided. Handling Deadlocks
Deadlock immune systemConstructing a system that guarantees deadlock never happens requires being able to break of the four conditions mentioned earlier. Recovery Tactics
Inclass code review: tie.chttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes/Deadlock Friday, November 7, 2014Instructor Slides =http://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes/KernSync Kernel - Safe Concurrent Accessasynchronous event servicing piece of code (interleaving control flow). Many interrupts are happening ; kernel can't afford to sit there and delay. Inherently, the kernel has many threads of control that might be modifying the same piece of state. The kernel attempts to provide for safe concurrent access via locking briefly at atomic operations. The kernel can preempt itself (interrupts its own kernel threads). NIC exampleConsider a NIC which receives data and then interrupts the CPU to specify that it received data; more data is likely to be on the way. Thus, this data needs to make it into RAM, so, the kernel interrupts a user level level process potentially and executes an interrupt service routine for the NIC to get this data moving. Atomic OperationsAccess with in 0 - 1 cycles Disabling / Enabling InterruptsOn a single processor system - disabling interrupts prior to an atomic operation would ensure that the process of performing this operation is not bothered by interrupts arriving because the current CPU is ignoring events. However on a multiprocessor system this methodology does not ensure safe concurrent access solely because the other CPUs are not paying attention to other CPUs and their respective disabled interrupts. A possible solution might then be - locking the memory bus. Kernel implementations for safe concurrent accessThe question is, how does the kernel implement some of these primitives ? (ie: spinlocks). Week 10Monday, November 10, 2014NO CLASS: READING BREAKWednesday, November 12, 2014IN CLASS: EXERCISE - pThreadsFriday, November 14, 2014Week 11Monday, November 17, 2014Instructor Notes/Slideshttp://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_457.F2014/Lecture_Notes/FileIO Wednesday, November 19, 2014Friday, November 21, 2014Week 12Monday, November 24, 2014Wednesday, November 26, 2014Friday, November 28, 2014Overview
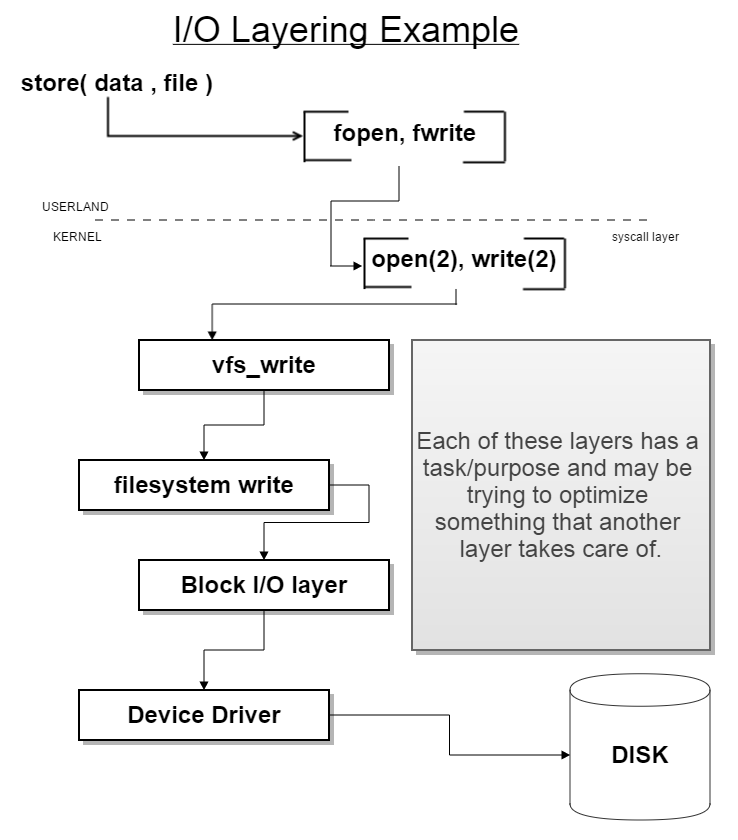
Main conceptsWant devices to offer random access but sometimes the physical properties of the real device make this slow, impractical or impossible. Elevator AlgorithmsUsed for dealing with writes to magnetic disks (mechanical device); have to be clever in how we order the requests. The OS needs to gather these requests and dispatch them; intelligent requests to the underlying hardware are required. I/O Layering Example
NOOP schedulingGood for SSD because SSDs are naturally/truly RAM. Disk IO Scan Example
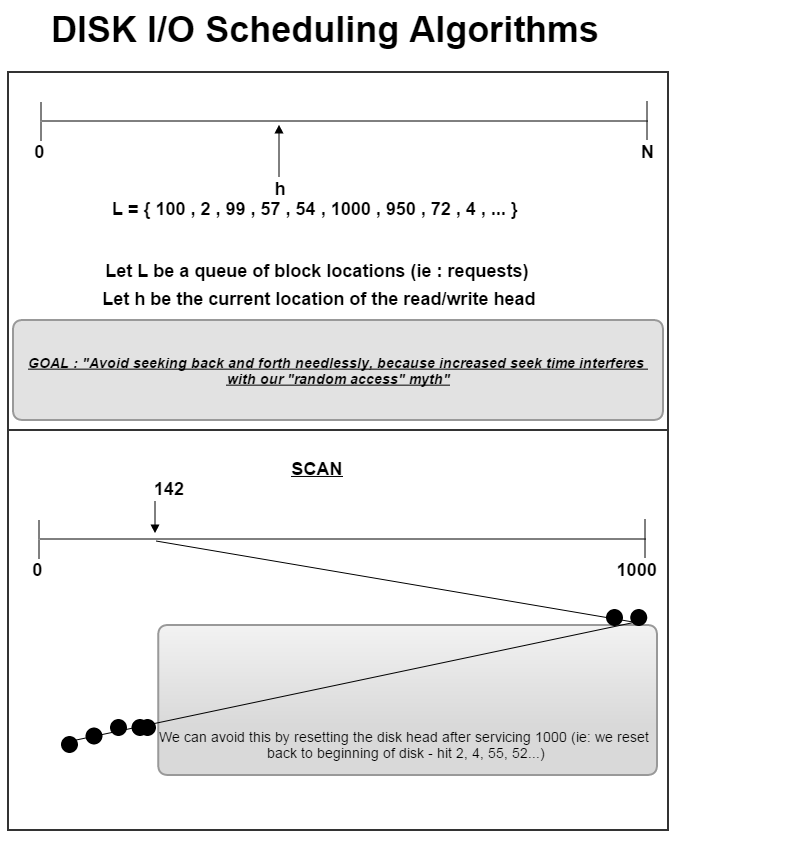
FCFSFirst-come, first-served SSTFShortest seek time first SCANStart at either end , move in one direction to other end. CSCANCircular scan - slight tweak on normal scan that improves upon it. Reset to start of disk and do not service intermediate requests like scan. LOOKFurther tweaking things out. Instead of needing to traverse to the end of disk just go to the highest point (ie: if it were 950) and also think about just going to 2. Final Exam ReviewReferences
|