Courses/Computer Science/CPSC 203/CPSC 203 Template/Labs Template/Week 1 - Lab 1: Intro to Databases (quick): Basic Parts of a Database
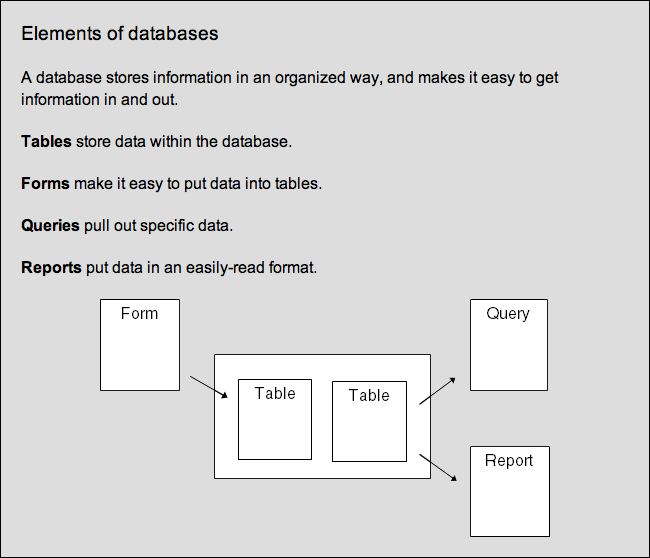
Contents
Notes
- Skills covered in this module:
- Basic parts of a Database
- Entity Relationship Diagrams
- A general overview and introduction to how a database is structured and works.
- Currently, sample screenshots are provided. Once a copy of Office 2007 is obtained, sample databases will be made, along with their corresponding screenshots.
Introduction to Databases
- Today's tutorial introduces the basic parts of a database, using MS Access.
At some point in our lives we all have (contact lists, records, finances, etc.) A spreadsheet is a good starting point, but often when there's a lot of information a database is more efficient. In this module the student will learn: What a database is, how information is structured and stored.
After completing this module, a student should be able to demonstrate the following skills:
- have an understanding of how information is structured and stored in a database
- will be able in the next lab to create a new database, setup tables and fields
Background Material Resources
- Computer Science Illuminated, Third Edition by Nell Dale and John Lewis
- ISBN-13:978-0-7637-4149-5
- http://www.jbpub.com
- Lab 8 page 177 of Fluency Computer Skills Workbook
Basic Foundations of Databases
- will have to define schema for students

A database is defined as a structured set of data. We're dealing with a particular type of database called a Relational Database. Relational Databases' are based on Set Theory in Mathematics. A database management system (DBMS) is a mixture of software and data that consist of:
1. The physical collection of files that contain data. 2. The software that allows users to interact with the database and make modifications. 3. The schema that specifies the logical structure of how the data is to be stored.
The type of database model we will be examining is the relational model, which is database model that organizes data and the relationship among them into tables. A table is defined as a collection of records. A record is a collection of related fields. Each field of a database table represents a single piece of data that is stored.
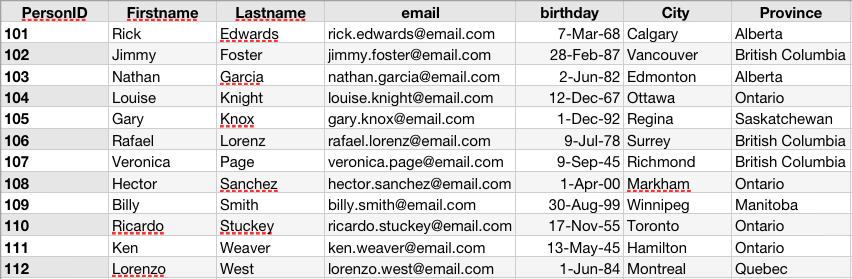
As an example, consider the database table below. It contains information about people (presumably an address book). Each row in the table corresponds to a record. Each record in the table is made up of the same fields in which a specific piece of data is stored. This is similar to how data is organized in spreadsheets.
- cross reference with material from the lectures
- http://wiki.ucalgary.ca/page/Courses/Computer_Science/CPSC_203/CPSC_203_2008Winter_L03/CPSC_203_2008Winter_L03_Lectures/Lecture_10

Each record in the address book has a personID, firstname, lastname, email, and birthday field that contains the specific data.
Usually one or more fields of a table have a key field. This field uniquely identifies a record in a database among other records in a table. In the address book table example, the personID field is the logical choice. That way if two or more people have the same first and last name they can still be uniquely identified and separated.
The structure of the table corresponds to the schema that it represents. The schema is an expression of the attributes of the records in a table, we can represent the schema of the address book as follows:
Address Book ( PersonID:key, Firstname, Lastname, Email, Birthday)
The advantage of using a relational database to store this type of information instead of a spreadsheet is the ability of a relational database management system to create tables that link various tables together.
Relationships
Records represent a collection of fields stored in a table. We can create records that combine or exclude fields to gather all the information we require.
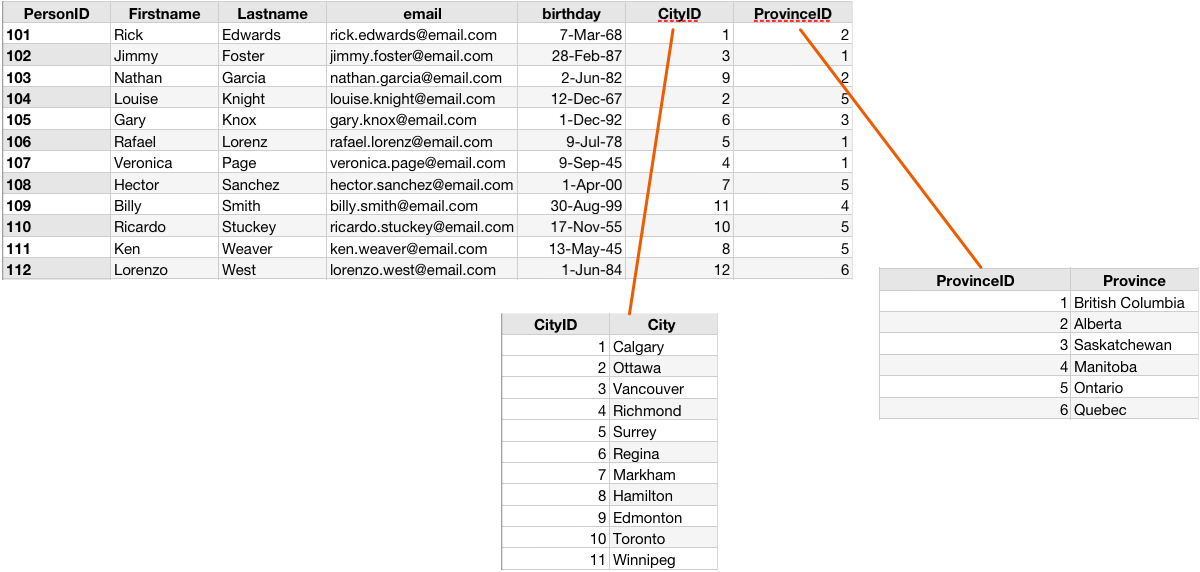
With our address book example, we will add on two fields to the database schema. We're going to add City and Province to the database schema. Because these two fields have information that repeats themselves, there is no point in creating this type of information repeatedly. For example, if one or more people live in the city of "Calgary" it would be easier to store that information in a separate table and then reference the city using a unique number ID.
In a relational database, the goal is to avoid duplicating such data. The image below demonstrates this concept, this table incorporates all the data but over time will grow substantially large and become very slow.

This design uses the relationship aspect to avoid using duplicate data. Here the cities and provinces are created once and then referenced multiple times. Also the table is smaller as it is only having to track numbers instead of containing the entire name of a city or province. That information can be referenced and pulled as needed when the user requires the city and/or province. Also if the user does not require the city or province then it is ignored and the results can be retrieved faster.